

抽取shtd_store库中user_info的增量数据进入Hudi的ods_ds_hudi库中表user_info。根据ods_ds_hudi.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这
两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,若operate_time为空,则用create_time填充,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.user_info命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
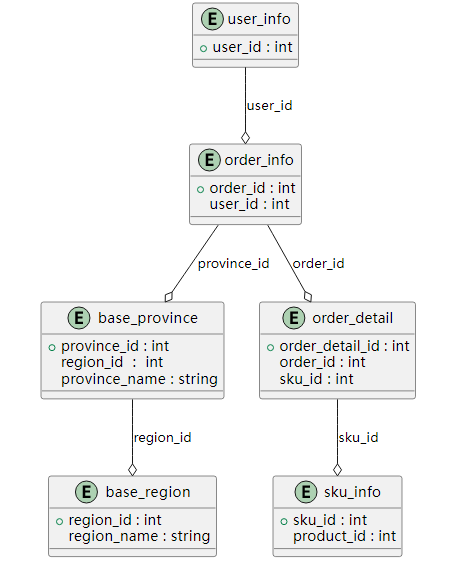
表关系示意图如下:
DROP TABLE IF EXISTS user_info;
CREATE TABLE user_info(
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '编号' ,
`login_name` VARCHAR(200) COMMENT '用户名称' ,
`nick_name` VARCHAR(200) COMMENT '用户昵称' ,
`passwd` VARCHAR(200) COMMENT '用户密码' ,
`name` VARCHAR(200) COMMENT '用户姓名' ,
`phone_num` VARCHAR(200) COMMENT '手机号' ,
`email` VARCHAR(200) COMMENT '邮箱' ,
`head_img` VARCHAR(200) COMMENT '头像' ,
`user_level` VARCHAR(200) COMMENT '用户级别' ,
`birthday` DATE COMMENT '用户生日' ,
`gender` VARCHAR(1) COMMENT '性别 M男,F女' ,
`create_time` DATETIME COMMENT '创建时间' ,
`operate_time` DATETIME COMMENT '修改时间' ,
PRIMARY KEY (id)
) COMMENT = '用户表';
DROP TABLE IF EXISTS sku_info;
CREATE TABLE sku_info(
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT 'skuid(itemID)' ,
`spu_id` BIGINT COMMENT 'spuid' ,
`price` DECIMAL(10) COMMENT '价格' ,
`sku_name` VARCHAR(200) COMMENT 'sku名称' ,
`sku_desc` VARCHAR(2000) COMMENT '商品规格描述' ,
`weight` DECIMAL(10,2) COMMENT '重量' ,
`tm_id` BIGINT COMMENT '品牌(冗余)' ,
`category3_id` BIGINT COMMENT '三级分类id(冗余)' ,
`sku_default_img` VARCHAR(200) COMMENT '默认显示图片(冗余)' ,
`create_time` DATETIME COMMENT '创建时间' ,
PRIMARY KEY (id)
) COMMENT = '库存单元表';
“Sku” 和 “Spu” 是与商品相关的两个重要概念,通常在零售和电子商务领域中使用。
-
SPU(Standard Product Unit) – 标准产品单元:
-
定义: SPU 是指标准产品单元,它代表一组具有相似属性的商品。通常,这组商品具有相同的基本特征,但可能存在一些细微的差异,例如颜色、尺寸等。
-
特点: SPU 是对一类产品的抽象,不同的具体商品属于同一个 SPU,因为它们共享相似的基本特征和用途。
-
例子: 以手机为例,一种型号的手机(如iPhone 12)可以被视为一个 SPU,因为它有相同的基本特征,如品牌、型号、屏幕大小等。
-
-
SKU(Stock Keeping Unit) – 存货量单位:
-
定义: SKU 是指存货量单位,它是对具体商品的唯一标识,通常包含了商品的唯一属性和识别信息,如颜色、尺寸、版本等。
-
特点: SKU 是对商品的具体变体或实例的描述,每个 SKU 都是唯一的。SKU 可以用于精确地跟踪和管理库存,方便售卖和库存管理。
-
例子: 如果以iPhone 12为SPU,那么不同颜色、不同存储容量和不同尺寸的iPhone 12就可以分别用不同的 SKU 进行标识,如”iPhone 12 – 红色 – 128GB”、”iPhone 12 – 蓝色 – 256GB”等。
-
在电商业务中,SPU 和 SKU 通常用于描述商品的层次结构和变体。SPU表示一类商品,而SKU则表示这类商品中的具体变体,有助于商家更好地管理商品库存、进行销售和满足客户的个性化需求。
DROP TABLE IF EXISTS base_province;
CREATE TABLE base_province(
`id` BIGINT COMMENT 'id' ,
`name` VARCHAR(20) COMMENT '省名称' ,
`region_id` VARCHAR(20) COMMENT '大区id' ,
`area_code` VARCHAR(20) COMMENT '行政区位码' ,
`iso_code` VARCHAR(20) COMMENT '国际编码'
) COMMENT = '省份';
DROP TABLE IF EXISTS base_region;
CREATE TABLE base_region(
`id` VARCHAR(20) COMMENT '大区id' ,
`region_name` VARCHAR(20) COMMENT '大区名称'
) COMMENT = '地区';
DROP TABLE IF EXISTS order_info;
CREATE TABLE order_info(
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '编号' ,
`consignee` VARCHAR(100) COMMENT '收货人' ,
`consignee_tel` VARCHAR(20) COMMENT '收件人电话' ,
`total_amount` DECIMAL(16,2) COMMENT '金额(手动新增字段)' ,
`final_total_amount` DECIMAL(16,2) COMMENT '总金额' ,
`order_status` VARCHAR(20) COMMENT '订单状态' ,
`user_id` BIGINT COMMENT '用户id' ,
`delivery_address` VARCHAR(1000) COMMENT '送货地址' ,
`order_comment` VARCHAR(200) COMMENT '订单备注' ,
`out_trade_no` VARCHAR(50) COMMENT '订单交易编号(第三方支付用)' ,
`trade_body` VARCHAR(200) COMMENT '订单描述(第三方支付用)' ,
`create_time` DATETIME COMMENT '创建时间' ,
`operate_time` DATETIME COMMENT '操作时间' ,
`expire_time` DATETIME COMMENT '失效时间' ,
`tracking_no` VARCHAR(100) COMMENT '物流单编号' ,
`parent_order_id` BIGINT COMMENT '父订单编号' ,
`img_url` VARCHAR(200) COMMENT '图片路径' ,
`province_id` INT COMMENT '地区' ,
`benefit_reduce_amount` DECIMAL(16,2) COMMENT '优惠金额' ,
`original_total_amount` DECIMAL(16,2) COMMENT '原价金额' ,
`feight_fee` DECIMAL(16,2) COMMENT '运费' ,
`payment_way` VARCHAR(30) COMMENT '支付方式' ,
PRIMARY KEY (id)
) COMMENT = '订单表 订单表';
DROP TABLE IF EXISTS order_detail;
CREATE TABLE order_detail(
`id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '编号' ,
`order_id` BIGINT COMMENT '订单编号' ,
`sku_id` BIGINT COMMENT 'sku_id' ,
`sku_name` VARCHAR(200) COMMENT 'sku名称(冗余)' ,
`img_url` VARCHAR(200) COMMENT '图片名称(冗余)' ,
`order_price` DECIMAL(10,2) COMMENT '购买价格(下单时sku价格)' ,
`sku_num` VARCHAR(200) COMMENT '购买个数' ,
`create_time` DATETIME COMMENT '创建时间' ,
PRIMARY KEY (id)
) COMMENT = '订单明细表';
抽取shtd_store库中user_info的增量数据进入Hudi的ods_ds_hudi库中表user_info。根据ods_ds_hudi.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,若operate_time为空,则用create_time填充,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.user_info命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
创建ods_ds_hudi.user_info表
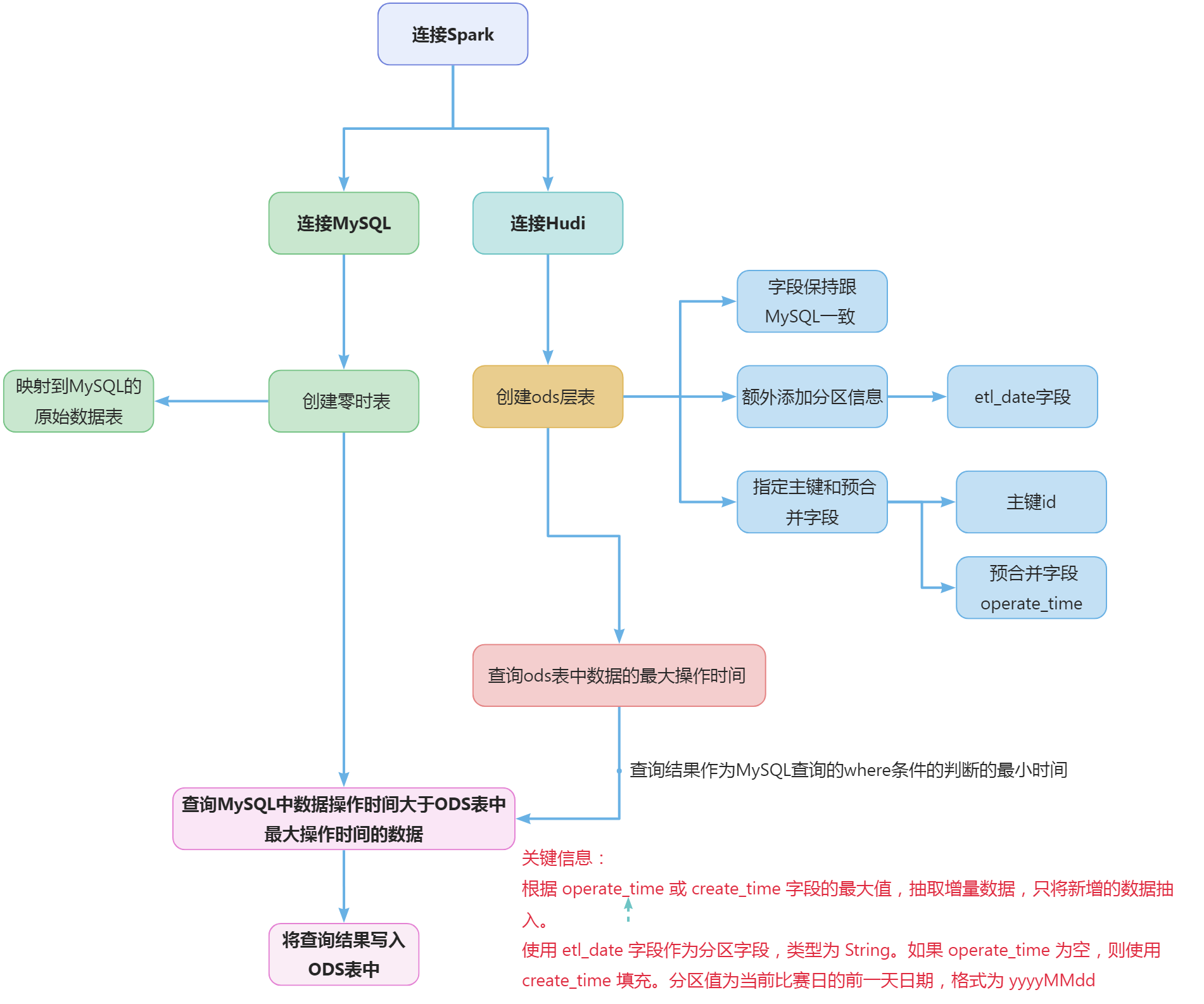
建表之前需要判断一下表是否存在,如果不存在才创建。涉及到两个概念,一个是ODS,一个是hudi。
-
在数据仓库(Data Warehouse)建模中, ODS(Operational Data Store,操作性数据存储)层 作为数据仓库架构的一部分,通常用于整合来自各种操作性系统的数据。这一层的主要目的是将这些数据整合到一个一致的、标准化的格式中,并进行清洗、转换以确保数据的质量。 一般来说ODS层只需要保存从数据库中抽取来的原始数据,不做任何的更改。 DWD (Data Warehouse Detailed Data) 层用于存储原始、详细的事务性数据,这些数据通常来自于企业的各个操作系统和数据源。这一层包含了数据仓库的底层原子数据,记录了每个操作的细节。 DWS层是DWD层的上一层,用于存储已经汇总和聚合过的数据。这一层的数据是经过处理、加工和聚合的,通常用于支持高层次的分析和决策。
-
Hudi(Hadoop Upserts Deletes and Incrementals)是一种开源的数据管理框架,旨在简化和优化Apache Hadoop和Apache Spark等大数据处理引擎上的数据湖(Data Lake)操作。Hudi 提供了一种方式,让用户更方便地实现增量数据存储、更新、删除以及实时查询等操作。
任务中要求分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。也就是说要根据etl_date时间不同,将抽取的数据放到对应etl时间的分区里,那么建表的时候就需要增加etl_date字段,类型为String。 任务要求中提到将id作为primaryKey,operate_time作为preCombineField。建表的时候需要配置表使用hudi,并且将id配置为主键,操作时间作为合并的字段。也就是说hudi会根据主键和操作时间来判断数据是插入还是更新。 建表语句如下:
spark.sql(
"""
|create table if not exists `ods_ds_hudi`.`user_info` (
| `id` int,
| `login_name` string,
| `nick_name` string,
| `passwd` string,
| `name` string,
| `phone_num` string,
| `email` string,
| `head_img` string,
| `user_level` string,
| `birthday` date,
| `gender` string,
| `create_time` timestamp,
| `operate_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'operate_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
语句中的如下部分是关于hudi的相关配置
using hudi
options (
type = 'cow',
primaryKey = 'id',
preCombineField = 'operate_time'
)
-
using hudi: 这一部分指定了使用 Hudi 进行数据操作。
-
options: 这是 Hudi SQL 的 options 子句,用于指定 Hudi 表的一些配置选项。
-
type = ‘cow’: 这个选项指定了 Hudi 表的写入类型,这里是 ‘cow’,表示 Copy on Write。Copy on Write 是 Hudi 的一种存储引擎,它在写入时会复制数据,保留历史版本。与之相对的是 ‘mor’(Merge on Read),它在写入时只更新最新版本,而历史版本会在查询时进行合并。
-
primaryKey = ‘id’: 这个选项指定了主键,即在 Hudi 表中用于唯一标识每条记录的字段。在这里,主键是 ‘id’。
-
preCombineField = ‘operate_time’: 这个选项指定了用于决定版本顺序的字段。Hudi 会使用这个字段的值来判断历史版本的先后顺序。在这里,使用了 ‘operate_time’ 字段。
综合起来,这条 SQL 语句表示要使用 Hudi 操作数据,表的写入类型为 Copy on Write,主键是 ‘id’,并且版本的顺序是通过 ‘operate_time’ 字段来确定的。这些配置可以根据具体的需求进行调整。
如何在spark中查询MySQL中的数据
需要将MySQL中表映射到sparksql中。
spark.sql(
"""
| create temporary view user_info_tmp
| using org.apache.spark.sql.jdbc
|options(
| url 'jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8',
| dbtable 'user_info',
| user 'root1',
| password '123456'
|)
|""".stripMargin)
-
create temporary view user_info_tmp: 这部分创建了一个临时视图(temporary view)叫做 “user_info_tmp”。这个视图用于在 Spark 中表示和查询 “user_info” 表的数据。
-
using org.apache.spark.sql.jdbc: 这表明使用了 JDBC 数据源来读取外部数据。具体地,这里使用的是 Spark SQL 的 JDBC 数据源。
-
options(…): 这里指定了连接 JDBC 数据源时的一些配置选项。
-
url ‘jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8’: 指定了 MySQL 数据库的连接信息,包括数据库地址、端口以及其他连接参数。
-
dbtable ‘user_info’: 指定了要读取的数据库表,这里是 “user_info”。
-
user ‘root1’: 指定了连接数据库所使用的用户名。
-
password ‘123456’: 指定了连接数据库所使用的密码。
-
-
stripMargin: 这是 Scala 语言中的一个特性,用于在多行字符串中去掉每行前面的空格。
获取比赛前一天新增的数据
从MySQL中查询出比赛前一天新增的数据,也就是创建时间是比赛前一天的数据。
select
`id`,
`login_name`,
`nick_name`,
`passwd`,
`name`,
`phone_num`,
`email`,
`head_img`,
`user_level`,
`birthday`,
`gender`,
`create_time`,
`operate_time`
from user_info_tmp where create_time >= '2023-09-01 00:00:00';
获取比赛前一天更新的数据
从MySQL中查询出比赛前一天更新的数据,也就是更新时间是比赛前一天的数据。
select
`id`,
`login_name`,
`nick_name`,
`passwd`,
`name`,
`phone_num`,
`email`,
`head_img`,
`user_level`,
`birthday`,
`gender`,
`create_time`,
`operate_time`
from user_info_tmp where operate_time >= '2023-09-01 00:00:00';
整合新增和更新的查询语句
将更新和新增的查询语句合并成一条sql语句,实现若operate_time为空,则用create_time填充的业务需求,sql如下:
select
`id`,
`login_name`,
`nick_name`,
`passwd`,
`name`,
`phone_num`,
`email`,
`head_img`,
`user_level`,
`birthday`,
`gender`,
`create_time`,
`operate_time`
from user_info_tmp where coalesce(`operate_time`, `create_time`) >= '2023-09-01 00:00:00';
coalesce(…, ”):COALESCE 函数用于返回参数列表中的第一个非空表达式。在这里,如果 ‘operate_time’字段值为空,那么返回 ‘create_time’字段的值。
如何确定更新多少数据
思考两个问题: 第一次导入的时候ods层中没有历史数据,如何处理? 某段时间没有定时导入数据到ods层中,新增和更新的数据时间使用数据抽取的时间是否合理? 以上两种问题就会导致数据导入不完整,故而任务要求中说“根据ods_ds_hudi.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入”。意思就是说要根据ODS层中历史数据的最近的操作时间(operate_time或create_time谁最新)来确定从MySQL中抽取哪段时间的数据。所以需要从ods层中查询出最大的操作时间。
select
case
when max(`operate_time`) > max(`create_time`)
then max(`operate_time`)
else max(`create_time`)
end
from `ods_ds_hudi`.`user_info`
case when max(operate_time) > max(create_time) then max(operate_time) else max(create_time) end: 这是一个 CASE 语句,用于根据条件判断选择不同的值。具体地,它比较 operate_time 列的最大值和 create_time 列的最大值,如果 operate_time 大于 create_time,则选择 operate_time 的最大值,否则选择 create_time 的最大值。
如果ods层的表中没有数据,那么这时候查到的值为空,这时候需要给个默认值,sql如下:
select
coalesce(
case
when max(`operate_time`) > max(`create_time`) then max(`operate_time`)
else max(`create_time`)
end, ''
)
from `ods_ds_hudi`.`user_info`
coalesce(…, ”):COALESCE 函数用于返回参数列表中的第一个非空表达式。在这里,如果 CASE 语句的结果为空,那么返回空字符串 ” 在sql中日期的比较可以转换成字符串来比较,将查询到的最大时间转换为字符串,sql如下:
select
cast(
coalesce(
case
when max(`operate_time`) > max(`create_time`) then max(`operate_time`)
else max(`create_time`)
end, ''
) as string
)
from `ods_ds_hudi`.`user_info`
cast(… as string):CAST 函数用于将结果转换为指定的数据类型。在这里,将前面的结果强制转换为字符串类型。 综合起来,整个查询的目的是从 ods_ds_hudi 数据库的 user_info 表中选择一个字符串值,该值是根据比较 operate_time 和 create_time 列的最大值而确定的。如果 operate_time 的最大值大于 create_time 的最大值,则选择 operate_time 的最大值,否则选择 create_time 的最大值。如果这个值为空,那么返回一个空字符串。
从MySQL中查询操作时间大于等于ODS层中最大时间的数据
将查询的ods层中最大的时间作为查询更新数据的参数,将最大时间查询作为子查询放到where条件中,sql如下:
select
`id`,
`login_name`,
`nick_name`,
`passwd`,
`name`,
`phone_num`,
`email`,
`head_img`,
`user_level`,
`birthday`,
`gender`,
`create_time`,
`operate_time`
from user_info_tmp
where
cast(coalesce(`operate_time`, `create_time`) as string) >=
(
select
cast(
coalesce(
case
when max(`operate_time`) > max(`create_time`) then max(`operate_time`)
else max(`create_time`)
end, ''
) as string
)
from `ods_ds_hudi`.`user_info`
);
where cast(coalesce(operate_time, create_time) as string) >= …: 这是一个 WHERE 子句,用于过滤数据。它选择了满足条件的行,条件是 operate_time 列或 create_time 列的非空最大值(作为字符串形式)要大于等于子查询的结果。 select cast(coalesce(case when max(operate_time) > max(create_time) then max(operate_time) else max(create_time) end, ”) as string) from ods_ds_hudi.user_info“: 这是一个子查询,它计算了 ods_ds_hudi 数据库中 user_info 表中的 operate_time 和 create_time 列的非空最大值。这个值将被用于与外部查询中的条件比较。
将查询到的更新数据插入到ods_ds_hudi.user_info表中
结合上面的操作,只需要将查询结果直接插入到ods层的表中即可,sql如下:
insert into `ods_ds_hudi`.`user_info` partition(etl_date = '20230901')
select
`id`,
`login_name`,
`nick_name`,
`passwd`,
`name`,
`phone_num`,
`email`,
`head_img`,
`user_level`,
`birthday`,
`gender`,
`create_time`,
`operate_time`
from user_info_tmp
where
cast(coalesce(`operate_time`, `create_time`) as string) >=
(
select
cast(
coalesce(
case
when max(`operate_time`) > max(`create_time`) then max(`operate_time`)
else max(`create_time`)
end, ''
) as string
)
from `ods_ds_hudi`.`user_info`
);
insert into ods_ds_hudi.user_info partition(etl_date = ‘20230901’): 这部分指定了数据插入的目标表,即 ods_ds_hudi.user_info,并指定了插入的分区为 etl_date = ‘20230901’。这表示数据将插入到指定分区中。
查看分区
spark.sql("show partitions `ods_ds_hudi`.`user_info` ").show()
抽取shtd_store库中sku_info的增量数据进入Hudi的ods_ds_hudi库中表sku_info。根据ods_ds_hudi.sku_info表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.sku_info命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
解题思路同任务要求1
spark.sql(
"""
|create table if not exists `ods_ds_hudi`.`sku_info` (
| `id` int,
| `spu_id` int,
| `price` decimal,
| `sku_name` string,
| `sku_desc` string,
| `weight` decimal,
| `tm_id` int,
| `category3_id` int,
| `sku_default_img` string,
| `create_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'create_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
spark.sql(
"""
| create temporary view sku_info_tmp
| using org.apache.spark.sql.jdbc
|options(
| url 'jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8',
| dbtable 'sku_info',
| user 'root1',
| password '123456'
|)
|""".stripMargin)
spark.sql("alter table `ods_ds_hudi`.`sku_info` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `ods_ds_hudi`.`sku_info` partition(etl_date = '20230901')
|select
| `id`,
| `spu_id`,
| `price`,
| `sku_name`,
| `sku_desc`,
| `weight`,
| `tm_id`,
| `category3_id`,
| `sku_default_img`,
| `create_time`
| from sku_info_tmp
| where
| cast(`create_time` as string)>(select cast(coalesce(max(`create_time`),'') as string) from `ods_ds_hudi`.`sku_info` )
|""".stripMargin)
spark.sql("show partitions `ods_ds_hudi`.`sku_info`").show()
抽取shtd_store库中base_province的增量数据进入Hudi的ods_ds_hudi库中表base_province。根据ods_ds_hudi.base_province表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.base_province命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
解题思路同任务要求1
spark.sql(
"""
|create table if not exists `ods_ds_hudi`.`base_province` (
| `id` int,
| `name` string,
| `region_id` string,
| `area_code` string,
| `iso_code` string,
| `create_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'create_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
spark.sql(
"""
| create temporary view base_province_tmp
| using org.apache.spark.sql.jdbc
|options(
| url 'jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8',
| dbtable 'base_province',
| user 'root1',
| password '123456'
|)
|""".stripMargin)
spark.sql("alter table `ods_ds_hudi`.`base_province` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `ods_ds_hudi`.`base_province` partition(etl_date = '20230901')
|select
| `id`,
| `name`,
| `region_id`,
| `area_code`,
| `iso_code`,
| current_timestamp as `create_time`
| from base_province_tmp
| where
| cast(`id` as string)>(select cast(coalesce(max(`id`),'') as string) from `ods_ds_hudi`.`base_province` )
|""".stripMargin)
spark.sql("show partitions `ods_ds_hudi`.`base_province`").show()
抽取shtd_store库中base_region的增量数据进入Hudi的ods_ds_hudi库中表base_region。根据ods_ds_hudi.base_region表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.base_region命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
解题思路同任务要求1
spark.sql(
"""
|create table if not exists `ods_ds_hudi`.`base_region` (
| `id` string,
| `region_name` string,
| `create_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'create_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
spark.sql(
"""
| create temporary view base_region_tmp
| using org.apache.spark.sql.jdbc
|options(
| url 'jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8',
| dbtable 'base_region',
| user 'root1',
| password '123456'
|)
|""".stripMargin)
spark.sql("alter table `ods_ds_hudi`.`base_region` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `ods_ds_hudi`.`base_region` partition(etl_date = '20230901')
|select
| `id`,
| `region_name`,
| current_timestamp as `create_time`
| from base_region_tmp
| where
| cast(`id` as string)>(select cast(coalesce(max(`id`),'') as string) from `ods_ds_hudi`.`base_region` )
|""".stripMargin)
spark.sql("show partitions `ods_ds_hudi`.`base_region`").show()
抽取shtd_store库中order_info的增量数据进入Hudi的ods_ds_hudi库中表order_info,根据ods_ds_hudi.order_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.order_info命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
解题思路同任务要求1
spark.sql(
"""
|create table if not exists `ods_ds_hudi`.`order_info` (
| `id` int,
| `consignee` string,
| `consignee_tel` string,
| `total_amount` decimal,
| `order_status` string,
| `user_id` int,
| `delivery_address` string,
| `order_comment` string,
| `out_trade_no` string,
| `trade_body` string,
| `create_time` timestamp,
| `operate_time` timestamp,
| `expire_time` timestamp,
| `tracking_no` string,
| `parent_order_id` int,
| `img_url` string,
| `province_id` int,
| `benefit_reduce_amount` decimal,
| `original_total_amount` decimal,
| `feight_fee` decimal,
| `payment_way` string,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'operate_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
spark.sql(
"""
| create temporary view order_info_tmp
| using org.apache.spark.sql.jdbc
|options(
| url 'jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8',
| dbtable 'order_info',
| user 'root1',
| password '123456'
|)
|""".stripMargin)
spark.sql("alter table `ods_ds_hudi`.`order_info` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `ods_ds_hudi`.`order_info` partition(etl_date = '20230901')
|select
| `id`,
| `consignee` ,
| `consignee_tel`,
| `total_amount`,
| `order_status`,
| `user_id`,
| `delivery_address`,
| `order_comment`,
| `out_trade_no`,
| `trade_body`,
| `create_time`,
| `operate_time`,
| `expire_time`,
| `tracking_no`,
| `parent_order_id`,
| `img_url`,
| `province_id`,
| `benefit_reduce_amount`,
| `original_total_amount`,
| `feight_fee`,
| `payment_way`
| from order_info_tmp
| where
| cast(coalesce(`operate_time`,`create_time`) as string) >(select cast(coalesce(case when max(`operate_time`) > max(`create_time`) then max(`operate_time`) else max(`create_time`) end,'') as string) from `ods_ds_hudi`.`order_info` )
|""".stripMargin)
spark.sql("show partitions `ods_ds_hudi`.`order_info`").show()
抽取shtd_store库中order_detail的增量数据进入Hudi的ods_ds_hudi库中表order_detail,根据ods_ds_hudi.order_detail表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.order_detail命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下。
解题思路同任务要求1
spark.sql(
"""
|create table if not exists `ods_ds_hudi`.`order_detail` (
| `id` int,
| `order_id` int,
| `sku_id` int,
| `sku_name` string,
| `img_url` string,
| `order_price` decimal,
| `sku_num` int,
| `create_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'create_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
spark.sql(
"""
| create temporary view order_detail_tmp
| using org.apache.spark.sql.jdbc
|options(
| url 'jdbc:mysql://127.0.0.1:3306/shtd_store?useSSL=false&useUnicode=true&characterEncoding=utf8',
| dbtable 'order_detail',
| user 'root1',
| password '123456'
|)
|""".stripMargin)
spark.sql("alter table `ods_ds_hudi`.`order_detail` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `ods_ds_hudi`.`order_detail` partition(etl_date = '20230901')
|select
| `id`,
| `order_id`,
| `sku_id`,
| `sku_name`,
| `img_url`,
| `order_price`,
| `sku_num`,
| `create_time`
| from order_detail_tmp
| where
| cast(`create_time` as string) >(select cast(coalesce(max(`create_time`),'') as string) from `ods_ds_hudi`.`order_detail` )
|""".stripMargin)
spark.sql("show partitions `ods_ds_hudi`.`order_detail`").show()
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。













暂无评论内容