

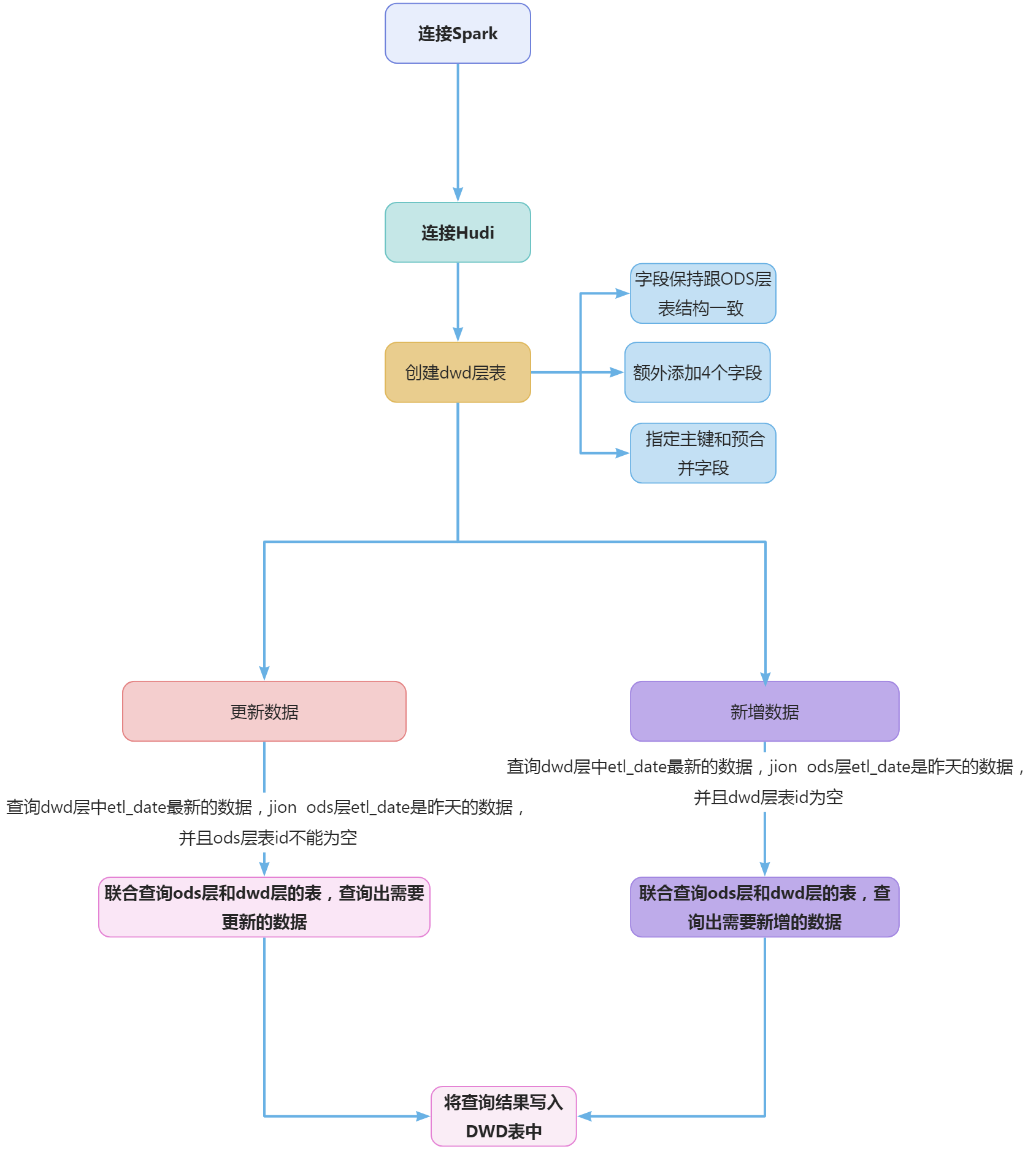
抽取ods_ds_hudi库base_region表中昨天的分区(子任务一生成的分区)数据,并结合dim_region最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_region的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_region最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
连接spark
spark-shell --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
创建dim_user_info表
根据要求:dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据operate_time排序取最新的一条,分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列。需要指定id为hudi的主键,operate_time为合并数据字段,分区字段为etl_date,并且在ods_ds_hudi库ods_user_info表结构的基础上增加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列。故建表语句如下:
spark.sql(
"""
|create table if not exists `dwd_ds_hudi`.`dim_user_info` (
| `id` int,
| `login_name` string,
| `nick_name` string,
| `passwd` string,
| `name` string,
| `phone_num` string,
| `email` string,
| `head_img` string,
| `user_level` string,
| `birthday` date,
| `gender` string,
| `create_time` timestamp,
| `operate_time` timestamp,
| `dwd_insert_user` string,
| `dwd_insert_time` timestamp,
| `dwd_modify_user` string,
| `dwd_modify_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'operate_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
插入更新数据
根据要求:若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,operate_time作为preCombineField。如果是更新数据需要修改dwd_modify_time和dwd_modify_user为当前时间和当前操作的人“user1”。 实现数据更新,也就是查询出dwd层中和ods层中最新etl_date的相同数据,然后写入到dwd层的表中。 dwd层中最新的数据需要查询出最新的etl_date。
select * from `dwd_ds_hudi`.`dim_user_info`
where etl_date=
(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_user_info` )
ods层中最新的数据也就是etl_date为前一天的数据。
select * from `ods_ds_hudi`.`user_info` where etl_date='20230901'
将上面上面两个查询的结果进行jion,ods层中id不为null的数据就是两个库都存在的数据,这些数据就需要进行更新操作,也就是将ods层中对应的数据写入到dwd层的表中。
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_user_info` partition(etl_date = '20230901')
|select
| a.`id`,
| b.`login_name`,
| b.`nick_name`,
| b.`passwd`,
| b.`name`,
| b.`phone_num`,
| b.`email`,
| b.`head_img`,
| b.`user_level`,
| b.`birthday`,
| b.`gender`,
| b.`create_time`,
| b.`operate_time`,
| 'user1'as`dwd_insert_user`,
| a.`dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_user_info`
| where etl_date=(
| select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_user_info` )
| ) a
| left join
| (select * from `ods_ds_hudi`.`user_info` where etl_date='20230901' ) b
| on a.id=b.id
| where b.id is not null
|""".stripMargin)
插入新增数据
参考更新数据中的sql,a.id为null的数据是dwd的表中匹配不到的数据,也就是新增的数据。sql如下:
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_user_info` partition(etl_date = '20230901')
|select
| b.`id`,
| b.`login_name`,
| b.`nick_name`,
| b.`passwd`,
| b.`name`,
| b.`phone_num`,
| b.`email`,
| b.`head_img`,
| b.`user_level`,
| b.`birthday`,
| b.`gender`,
| b.`create_time`,
| b.`operate_time`,
| 'user1'as`dwd_insert_user`,
| current_timestamp as `dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_user_info`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_user_info` )) a
| right join
| (select * from `ods_ds_hudi`.`user_info` where etl_date='20230901' ) b
| on a.id=b.id
| where a.id is null
|""".stripMargin)
查看表分区
spark.sql("show partitions `dwd_ds_hudi`.`dim_user_info`").show()
抽取ods_ds_hudi库sku_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_sku_info最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_sku_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell查询表dim_sku_info的字段id、sku_desc、dwd_insert_user、dwd_modify_time、etl_date,条件为最新分区的数据,id大于等于15且小于等于20,并且按照id升序排序,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
建立dwd_ds_hudi.dim_sku_info hudi表,etl_date作为分区字段
spark.sql(
"""
|create table if not exists `dwd_ds_hudi`.`dim_sku_info` (
| `id` int,
| `spu_id` int,
| `price` decimal,
| `sku_name` string,
| `sku_desc` string,
| `weight` decimal,
| `tm_id` int,
| `category3_id` int,
| `sku_default_img` string,
| `create_time` timestamp,
| `dwd_insert_user` string,
| `dwd_insert_time` timestamp,
| `dwd_modify_user` string,
| `dwd_modify_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'dwd_modify_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
用ods_ds_hudi.sku_info hudi表按id更新dwd_ds_hudi.dim_sku_info hudi表中已经有的记录,两张表所用的分区均为比赛前一天,格式yyyyMMdd,如20230901
spark.sql("alter table `dwd_ds_hudi`.`dim_sku_info` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_sku_info` partition(etl_date = '20230901')
|select
| a.`id`,
| b.`spu_id`,
| b.`price`,
| b.`sku_name`,
| b.`sku_desc`,
| b.`weight`,
| b.`tm_id`,
| b.`category3_id`,
| b.`sku_default_img`,
| b.`create_time`,
| 'user1'as`dwd_insert_user`,
| a.`dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_sku_info`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_sku_info` )) a
| left join
| (select * from `ods_ds_hudi`.`sku_info` where etl_date='20230901' ) b
| on a.id=b.id
| where b.id is not null
|""".stripMargin)
用ods_ds_hudi.sku_info hudi表按id插入dwd_ds_hudi.dim_sku_info hudi表中没有的记录,`两张表所用的分区均为比赛前一天,格式yyyyMMdd,如20230901
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_sku_info` partition(etl_date = '20230901')
|select
| b.`id`,
| b.`spu_id`,
| b.`price`,
| b.`sku_name`,
| b.`sku_desc`,
| b.`weight`,
| b.`tm_id`,
| b.`category3_id`,
| b.`sku_default_img`,
| b.`create_time`,
| 'user1'as`dwd_insert_user`,
| current_timestamp as `dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_sku_info`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_sku_info` )) a
| right join
| (select * from `ods_ds_hudi`.`sku_info` where etl_date='20230901' ) b
| on a.id=b.id
| where a.id is null
|""".stripMargin)
使用spark-shell查询表dim_sku_info的字段id、sku_desc、dwd_insert_user、dwd_modify_time、etl_date,条件为最新分区的数据,id大于等于15且小于等于20,并且按照id升序排序
spark.sql("select id,sku_desc,dwd_insert_user,dwd_modify_time,etl_date from `dwd_ds_hudi`.`dim_sku_info` where id>=10 and id<=20 and etl_date=(select max(etl_date) from `dwd_ds_hudi`.`dim_sku_info`) order by id").show()
抽取ods_ds_hudi库base_province表中昨天的分区(子任务一生成的分区)数据,并结合dim_province最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_province的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_province最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
建立dwd_ds_hudi.dim_province hudi表,etl_date作为分区字段
spark.sql(
"""
|create table if not exists `dwd_ds_hudi`.`dim_province` (
| `id` int,
| `name` string,
| `region_id` string,
| `area_code` string,
| `iso_code` string,
| `create_time` timestamp,
| `dwd_insert_user` string,
| `dwd_insert_time` timestamp,
| `dwd_modify_user` string,
| `dwd_modify_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'dwd_modify_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
用ods_ds_hudi.base_province hudi表按id更新dwd_ds_hudi.dim_province hudi表中已经有的记录,两张表所用的分区均为比赛前一天,格式yyyyMMdd,如20230901
spark.sql("alter table `dwd_ds_hudi`.`dim_province` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_province` partition(etl_date = '20230901')
|select
| a.`id`,
| b.`name`,
| b.`region_id`,
| b.`area_code`,
| b.`iso_code` ,
| b.`create_time`,
| 'user1'as`dwd_insert_user`,
| a.`dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_province`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_province` )) a
| left join
| (select * from `ods_ds_hudi`.`base_province` where etl_date='20230901' ) b
| on a.id=b.id
| where b.id is not null
|""".stripMargin)
用ods_ds_hudi.base_province hudi表按id插入dwd_ds_hudi.dim_province hudi表中没有的记录,`两张表所用的分区均为比赛前一天,格式yyyyMMdd,如20230901
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_province` partition(etl_date = '20230901')
|select
| b.`id`,
| b.`name`,
| b.`region_id`,
| b.`area_code`,
| b.`iso_code` ,
| b.`create_time`,
| 'user1'as`dwd_insert_user`,
| current_timestamp as `dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_province`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_province` )) a
| right join
| (select * from `ods_ds_hudi`.`base_province` where etl_date='20230901' ) b
| on a.id=b.id
| where a.id is null
|""".stripMargin)
使用spark-shell在表dwd_ds_hudi.dim_province最新分区中,查询该分区中数据的条数
spark.sql("select count(1) from `dwd_ds_hudi`.`dim_province` where etl_date=(select max(etl_date) from `dwd_ds_hudi`.`dim_province`) ").show()
抽取ods_ds_hudi库base_region表中昨天的分区(子任务一生成的分区)数据,并结合dim_region最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_region的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_region最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
建立dwd_ds_hudi.dim_region hudi表,etl_date作为分区字段
spark.sql(
"""
|create table if not exists `dwd_ds_hudi`.`dim_region` (
| `id` string,
| `region_name` string,
| `create_time` timestamp,
| `dwd_insert_user` string,
| `dwd_insert_time` timestamp,
| `dwd_modify_user` string,
| `dwd_modify_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'dwd_modify_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
用ods_ds_hudi.base_region hudi表按id更新dwd_ds_hudi.dim_region hudi表中已经有的记录,两张表所用的分区均为比赛前一天,格式yyyyMMdd,如20230901
spark.sql("alter table `dwd_ds_hudi`.`dim_region` drop partition(etl_date = '20230901') ")
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_region` partition(etl_date = '20230901')
|select
| a.`id`,
| b.`region_name`,
| b.`create_time`,
| 'user1'as`dwd_insert_user`,
| a.`dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_region`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_region` )) a
| left join
| (select * from `ods_ds_hudi`.`base_region` where etl_date='20230901' ) b
| on a.id=b.id
| where b.id is not null
|""".stripMargin)
用ods_ds_hudi.base_region hudi表按id插入dwd_ds_hudi.dim_region hudi表中没有的记录,`两张表所用的分区均为比赛前一天,格式yyyyMMdd,如20230901
spark.sql(
"""
|insert into `dwd_ds_hudi`.`dim_region` partition(etl_date = '20230901')
|select
| b.`id`,
| b.`region_name`,
| b.`create_time`,
| 'user1'as`dwd_insert_user`,
| current_timestamp as `dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`
| from
| (select * from `dwd_ds_hudi`.`dim_region`where etl_date=(select coalesce(max(etl_date),'') from `dwd_ds_hudi`.`dim_region` )) a
| right join
| (select * from `ods_ds_hudi`.`base_region` where etl_date='20230901' ) b
| on a.id=b.id
| where a.id is null
|""".stripMargin)
使用spark-shell在表dwd_ds_hudi.dim_region最新分区中,查询该分区中数据的条数
spark.sql("select count(1) from `dwd_ds_hudi`.`dim_region` where etl_date=(select max(etl_date) from `dwd_ds_hudi`.`dim_region`) ").show()
将ods_ds_hudi库中order_info表昨天的分区(子任务一生成的分区)数据抽取到dwd_ds_hudi库中fact_order_info的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,同时若operate_time为空,则用create_time填充,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions dwd.fact_order_info命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下;
建立dwd_ds_hudi.fact_order_info hudi表,etl_date作为分区字段
spark.sql(
"""
|create table if not exists `dwd_ds_hudi`.`fact_order_info` (
| `id` int,
| `consignee` string,
| `consignee_tel` string,
| `total_amount` decimal,
| `order_status` string,
| `user_id` int,
| `delivery_address` string,
| `order_comment` string,
| `out_trade_no` string,
| `trade_body` string,
| `create_time` timestamp,
| `operate_time` timestamp,
| `expire_time` timestamp,
| `tracking_no` string,
| `parent_order_id` int,
| `img_url` string,
| `province_id` int,
| `benefit_reduce_amount` decimal,
| `original_total_amount` decimal,
| `feight_fee` decimal,
| `payment_way` string,
| `dwd_insert_user` string,
| `dwd_insert_time` timestamp,
| `dwd_modify_user` string,
| `dwd_modify_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'operate_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
用ods_ds_hudi.order_info hudi表按动态分区更新dwd_ds_hudi.fact_order_info hudi表,etl_date取create_time并转格式为yyyyMMdd,如20230901
spark.sql(
"""
|insert into `dwd_ds_hudi`.`fact_order_info`
|select
| `id`,
| `consignee`,
| `consignee_tel`,
| `total_amount`,
| `order_status`,
| `user_id`,
| `delivery_address`,
| `order_comment`,
| `out_trade_no`,
| `trade_body`,
| `create_time`,
| coalesce(`operate_time`,`create_time`) as `operate_time`,
| `expire_time`,
| `tracking_no`,
| `parent_order_id`,
| `img_url`,
| `province_id`,
| `benefit_reduce_amount`,
| `original_total_amount`,
| `feight_fee` ,
| `payment_way` ,
| 'user1' as `dwd_insert_user`,
| current_timestamp as `dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`,
| replace(SUBSTRING(`create_time`,0,10),'-','') as etl_date
| from
| (select * from `ods_ds_hudi`.`order_info` where etl_date='20230901' ) b
|""".stripMargin)
使用spark-shell执行show partitions dwd_ds_hudi.fact_order_info命令
spark.sql("show partitions `dwd_ds_hudi`.`fact_order_info`").show()
将ods_ds_hudi库中order_detail表昨天的分区(子任务一中生成的分区)数据抽取到dwd_ds_hudi库中fact_order_detail的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell执行show partitions dwd_ds_hudi.fact_order_detail命令,将结果截图粘贴至客户端桌面【Release任务B提交结果.docx】中对应的任务序号下。
建立dwd_ds_hudi.fact_order_detail hudi表,etl_date作为分区字段
spark.sql(
"""
|create table if not exists `dwd_ds_hudi`.`fact_order_detail` (
| `id` int,
| `order_id` int,
| `sku_id` int,
| `sku_name` string,
| `img_url` string,
| `order_price` decimal,
| `sku_num` int,
| `create_time` timestamp,
| `dwd_insert_user` string,
| `dwd_insert_time` timestamp,
| `dwd_modify_user` string,
| `dwd_modify_time` timestamp,
| `etl_date` string
| )using hudi
|options (
| type = 'cow',
| primaryKey = 'id',
| preCombineField = 'dwd_modify_time'
|)
|partitioned by (`etl_date`);
|""".stripMargin)
用ods_ds_hudi.order_detail hudi表按动态分区更新dwd_ds_hudi.fact_order_detail hudi表,etl_date取create_time并转格式为yyyyMMdd,如20230901
spark.sql(
"""
|insert into `dwd_ds_hudi`.`fact_order_detail`
|select
| `id`,
| `order_id`,
| `sku_id` ,
| `sku_name`,
| `img_url`,
| `order_price`,
| `sku_num`,
| `create_time`,
| 'user1'as`dwd_insert_user`,
| current_timestamp as `dwd_insert_time`,
| 'user1' as `dwd_modify_user`,
| current_timestamp as `dwd_modify_time`,
| replace(SUBSTRING(`create_time`,0,10),'-','') as etl_date
| from
| (select * from `ods_ds_hudi`.`order_detail` where etl_date='20230901' ) b
|""".stripMargin)
使用spark-shell执行show partitions dwd_ds_hudi.fact_order_detail命令
spark.sql("show partitions `dwd_ds_hudi`.`fact_order_detail`").show()
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。












暂无评论内容