


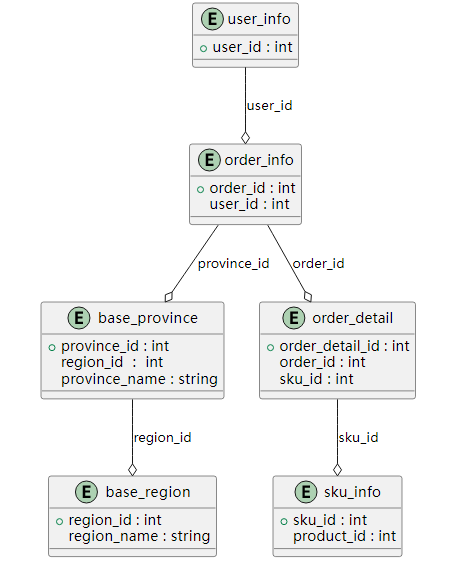
任务一:请描述HBase 的rowkey 设计原则。
任务描述
请简要描述HBase 的rowkey 的重要性并说明在设计rowkey 时应遵循哪些原则,将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
-
Rowkey的唯一原则
必须在设计上保证其唯一性。由于在HBase中数据存储是Key-Value形式,若HBase中同一表插入相同Rowkey,则原先的数据会被覆盖掉(如果表的version设置为1的话),所以务必保证Rowkey的唯一性。
-
Rowkey的排序原则
HBase的Rowkey是按照ASCII有序设计的,我们在设计Rowkey时要充分利用这点。比如视频网站上对影片《泰坦尼克号》的弹幕信息,这个弹幕是按照时间倒排序展示视频里,这个时候我们设计的Rowkey要和时间顺序相关。可以使用”Long.MAX_VALUE – 弹幕发表时间”的 long 值作为 Rowkey 的前缀。
-
Rowkey的散列原则
我们设计的Rowkey应均匀的分布在各个HBase节点上。拿常见的时间戳举例,假如Rowkey是按系统时间戳的方式递增,Rowkey的第一部分如果是时间戳信息的话将造成所有新数据都在一个RegionServer上堆积的热点现象,也就是通常说的Region热点问题, 热点发生在大量的client直接访问集中在个别RegionServer上(访问可能是读,写或者其他操作),导致单个RegionServer机器自身负载过高,引起性能下降甚至Region不可用,常见的是发生jvm full gc或者显示region too busy异常情况,当然这也会影响同一个RegionServer上的其他Region。
为了防止数据热点,可在设计Rowkey时采用如下几种有效措施:
(1)加盐。这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
(2)哈希。哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
(3)反转。第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题。
(4)时间戳反转。一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value – timestamp 追加到key的末尾,例如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计:[userId反转][Long.Max_Value – timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转][000000000000],stopRow是[userId反转][Long.Max_Value – timestamp]。如果需要查询某段时间的操作记录,startRow是[user反转][Long.Max_Value – 起始时间],stopRow是[userId反转][Long.Max_Value – 结束时间]。
-
Rowkey的长度原则
Rowkey是一个二进制,Rowkey的长度被很多开发者建议说设计在10~100个字节,建议是越短越好。原因有两点:
-
其一是HBase的持久化文件HFile是按照KeyValue存储的,如果Rowkey过长比如500个字节,1000万列数据仅Rowkey就要占用500*1000万=50亿个字节,将近1G数据,这会极大影响HFile的存储效率;
-
其二是MemStore缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低,系统无法缓存更多的数据,这会降低检索效率;
需要指出的是不仅Rowkey的长度是越短越好,而且列族名、列名等尽量使用短名字,因为HBase属于列式数据库,这些名字都是会写入到HBase的持久化文件HFile中去,过长的Rowkey、列族、列名都会导致整体的存储量成倍增加。
任务二:ClickHouse 有哪些表引擎?列举四种并简要描述。
任务描述
ClickHouse 有哪些表引擎?列举四种并简要描述。将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
表引擎是ClickHouse设计实现中的一大特色。表引擎决定了:
-
数据存储和读取的位置
-
支持哪些查询方式
-
能否并发式访问数据
-
能不能使用索引
-
是否可以执行多线程请求
-
数据复制使用的参数
ClickHouse拥有庞大的表引擎体系,包括MergeTree系列引擎、日志(Log)引擎、集成(Integrations)表引擎和特殊(Special)表引擎共4大类20多种。
我这里列举其中四种表引擎,并进行简要描述。
1)MergeTree
MergeTree表引擎用于插入极大量的数据到一张表中,数据以数据片段的形式一个接着一个的快速写入,数据片段按照一定的规则进行合并。
它适用于高负载任务,支持大数据量的快速写入并进行后续的数据处理,通用程度高且功能强大。它的特点是支持数据副本、分区、数据采样等特性。
2)Log
Log表引擎支持并发读取数据文件,每个列会单独存储在一个独立文件中,查询性能比较好。
它适用于快速写入小表(1百万行左右的表)并读取全部数据的场景。它的特点包括:数据被追加写入磁盘中;不支持delete、update; 不支持索引;不支持原子性写;insert会阻塞select操作。
3)Kafka
Kafka表引擎属于集成表引擎,用于将Kafka Topic中的数据直接导入到数据库ClickHouse。
它适用于将外部数据导入到数据库ClickHouse中,或者在数据库ClickHouse中直接使用外部数据源。
4)Memory
Memory表引擎将数据存储在内存中,重启后会导致数据丢失。查询性能极好,适合于对于数据持久性没有要求的1亿以下的小表。在云数据库ClickHouse中,通常用来做临时表。
它适用于特定的功能场景。
任务三:对于分组排序的理解。
任务描述
请问Hive SQL 有哪三种分组排序,他们各自的特点是什么?将内容编写至对应报告中将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
hive中可用于分组排序的函数主要有:row_number,rank,dense_rank,它们分别有不同的特点。
-
(1) row_number:排序时给每一行分配唯一的顺序,相同行顺序也不同。
-
(2) rank:相同行会分配相同的顺序,但是接下来会跳跃排序。
-
(3) dense_rank:为相同行分配同样的顺序,但是接下来的顺序也是连续的,不是跳跃的。
任务四:Kafka 中的数据如何保证不丢失?
任务描述
在任务D 中使用到了Kafka,将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
Kafka 的整个架构非常简洁,是分布式的架构,主要由 Producer、Broker、Consumer 三部分组成。一条消息从产生,到发送到kafka保存,到被取出消费,会有多个场景和流程阶段,因此剖析丢失场景会从 Producer、Broker、Consumer 这三部分入手来剖析。
1)生产者数据的不丢失
Kafka的ack机制:在Kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够被收到,其中状态有0、1、-1。
如果是同步模式:ack机制能够保证数据的不丢失,如果ack设置为0,风险很大,一般不建议设置为0。即使设置为1,也会随着leader宕机丢失数据。
producer.type=sync
request.required.acks=1
如果是异步模式:也会考虑ack的状态,除此之外,异步模式下的有个buffer,通过buffer来进行控制数据的发送。有两个值来进行控制:时间阈值与消息的数量阈值。如果buffer满了数据还没有发送出去,有个选项是配置是否立即清空buffer。可以设置为-1,永久阻塞,也就数据不再生产。异步模式下,即使设置为-1。也可能因为程序员的不科学操作,操作数据丢失,比如kill -9,但这是特别的例外情况。
producer.type=async
request.required.acks=1
queue.buffering.max.ms=5000
queue.buffering.max.messages=10000
queue.enqueue.timeout.ms=-1
batch.num.messages=200
结论:producer有丢数据的可能,但是可以通过配置保证消息的不丢失。
2)消费者数据的不丢失
通过offset commit 来保证数据的不丢失,Kafka自己记录了每次消费的offset数值,下次继续消费的时候,会接着上次的offset进行消费。
而offset的信息在Kafka0.8版本之前保存在Zookeeper中,在0.8版本之后保存到topic中,即使消费者在运行过程中挂掉了,再次启动的时候会找到offset的值,找到之前消费消息的位置,接着消费,由于 offset的信息写入的时候并不是每条消息消费完成后都写入的,所以这种情况有可能会造成重复消费,但是不会丢失消息。
唯一例外的情况是,我们在程序中给原本做不同功能的两个consumer组设置KafkaSpoutConfig.bulider.setGroupid的时候设置成了一样的groupid,这种情况会导致这两个组共享同一份数据,就会产生组A消费partition1、partition2中的消息,组B消费partition3的消息,这样每个组消费的消息都会丢失,都是不完整的。 为了保证每个组都独享一份消息数据,groupid一定不要重复才行。
3)Kafka集群中的broker的数据不丢失
每个broker中的partition我们一般都会设置有replication(副本)的个数,生产者写入的时候首先根据分发策略(有partition按partition,有key按key,都没有轮询)写入到leader中,follower(副本)再跟leader同步数据,这样有了备份,也可以保证消息数据的不丢失。
任务五:Spark 的数据本地性有哪几种,分别表示什么?
任务描述
在任务B 与任务C 中使用到了Spark,其中有些JOB 运行较慢,有些较快,一部分原因与数据位置和计算位置相关,其数据本地性可以在SparkUI 中查看到。请问Spark 的数据本地性有哪几种(英文)?分别表示的含义是什么(中文)?将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
大数据中有一个很有名的概念就是“移动数据不如移动计算”,之所以有数据本地性就是因为数据在网络中传输会有不小的I/O消耗,如果能够想办法尽量减少这个I/O消耗就能够提升效率。那么如何减少I/O消耗呢,当然是尽量不让数据在网络上传输,即使无法避免数据在网络上传输,也要尽量缩短传输距离,这个数据需要传输多远的距离(实际意味着数据传输的代价)就是数据本地性,数据本地性根据传输距离分为几个级别,不在网络上传输肯定是最好的级别,其它级别划分依据传输距离越远级别越低,Spark在分配任务的时候会考虑到数据本地性,优先将任务分配给数据本地性最好的Executor执行。
数据本地性共分为五个级别:
-
PROCESS_LOCAL:顾名思义,要处理的数据就在同一个本地进程中,即数据和Task在同一个Executor JVM中,这种情况就是RDD的数据在之前就已经被缓存过了,因为BlockManager是以Executor为单位的,所以只要Task所需要的Block在所属的Executor的BlockManager上已经被缓存,这个数据本地性就是PROCESS_LOCAL,这种是最好的locality,这种情况下数据不需要在网络中传输。
-
NODE_LOCAL:数据在同一台节点上,但是并不不在同一个jvm中,比如数据在同一台节点上的另外一个Executor上,速度要比PROCESS_LOCAL略慢。还有一种情况是读取HDFS的块就在当前节点上,数据本地性也是NODE_LOCAL。
-
NO_PREF:数据从哪里访问都一样,表示数据本地性无意义,看起来很奇怪,其实指的是从MySQL、MongoDB之类的数据源读取数据。
-
RACK_LOCAL:数据在同一机架上的其它节点,需要经过网络传输,速度要比NODE_LOCAL慢。
-
ANY:数据在其它更远的网络上,甚至都不在同一个机架上,比RACK_LOCAL更慢,一般情况下不会出现这种级别,万一出现了可能是有什么异常需要排查下原因。
任务六:请简述Spark 中共享变量的基本原理和用途。
任务描述
请简述Spark 中共享变量的基本原理和用途, 将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
Spark中共享变量包括广播变量和累加器。
1)累加器
累加器可以理解为一种分布式变量,其在driver端创建并赋初值,随着任务的分发在taskExecutor执行更新。
累加器只能在driver端读取,不能在executor端读取,在executor端可以通过add方法累加,不同executor的累加互不影响,executor是task级别的。
2)广播变量
用来分发较大的对象,以供一个或多个Spark操作符使用。
在多个并行操作中使用同一个变量时,Spark会为每个任务分别发送。对应闭包中某些变量,会随着task任务的分发而分发,因为闭包数据以task为单位发送,每个任务包含闭包数据。例如,如果有1000个任务,则会被分发1000次,且被缓存1000次,这将造成较多的冗余数据,过多消耗内存,影响作业运行性能。
Spark使用广播在task分发之前将变量发送到executor,将闭包的数保存到Executor的内存中(只读)。同一个executor的多个task共享这个变量,降低了任务分发时的消耗和内存消耗。Executor 即相当于一个JVM进程,启动时会自动分配内存,将任务中的闭包数据放置在Executor的内存中达到共享目的。
rdd不能被广播,如果要广播rdd,需要使用collect算子将数据汇总到driver,然后广播数据。
executor不能修改广播数据,广播数据是只读的。
3)用途
累加器可以用在诸如统计全局次数之类的场景。
广播变量用在优化shuffle、提升性能的场景。
任务七:请简述Flink 资源管理中Task Slot 的概念。
任务描述
请简述你对Task Slot 的理解,将内容编写至客户端桌面【Release\模块F 提交结果.docx】中对应的任务序号下。
参考答案:
在Flink架构中,TaskManager是实际负责执行计算的Worker。TaskManager是一个JVM进程,并会以独立的线程来执行一个task或多个subtask。
为了控制一个TaskManager能接受多少个task,Flink提出了Task Slot的概念。TaskManager中最细粒度的资源是Task slot,代表了一个固定大小的资源子集。简单的说,TaskManager会将自己节点上管理的资源分为不同的Slot(固定大小的资源子集)。这样就避免了不同Job的Task互相竞争内存资源。
通过调整task slot的数量,用户可以定义task之间是如何相互隔离的。每个TaskManager有一个slot,也就意味着每个task运行在独立的JVM中。每个TaskManager有多个slot的话,也就是说多个task运行在同一个JVM中。
而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输,也能共享一些数据结构,一定程度上减少了每个task的消耗。 每个slot可以接受单个task,也可以接受多个连续task组成的pipeline。
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。










暂无评论内容