
大数据国赛培训2023 第2页
本赛项涉及的典型工作任务包括大数据平台搭建(容器环境)、离线数据处理、数据挖掘、数据采集与实时计算、数据可视化、综合分析、职业素养,引入行业内较为前沿的数据湖架构作为创新、创意的范围与方向。
排序
5-4.大数据国赛数据可视化-用条形图展示消费总额最高的省份
实验环境实验准备实验内容一、下载安装vue cli二、创建vue.js项目三、编辑App.vue添加MyCharts组件四、写出MyCharts数据可视化组件模板代码五、在模板里添加处理数据的逻辑代码 实验环境Ubun...
2-2.大数据国赛第2套任务B-子任务二数据清洗
任务要求11.1实现流程概要1.2任务分解任务要求22.1创建表2.2按id更新数据2.3按id插入数据2.4查询数据任务要求33.1创建表3.2按Id更新数据3.3按ld插入数据3.4查询数据任务要求44.1创建表4.2按Id更...
5-5.大数据国赛数据可视化-折柱混合图展示省份和地区平均消费额
实验环境实验准备实验内容一、下载安装vue cli二、创建vue.js项目三、编辑App.vue添加MyCharts组件四、写出MyCharts数据可视化组件模板代码五、在模板里添加处理数据的逻辑代码 实验环境Ubun...

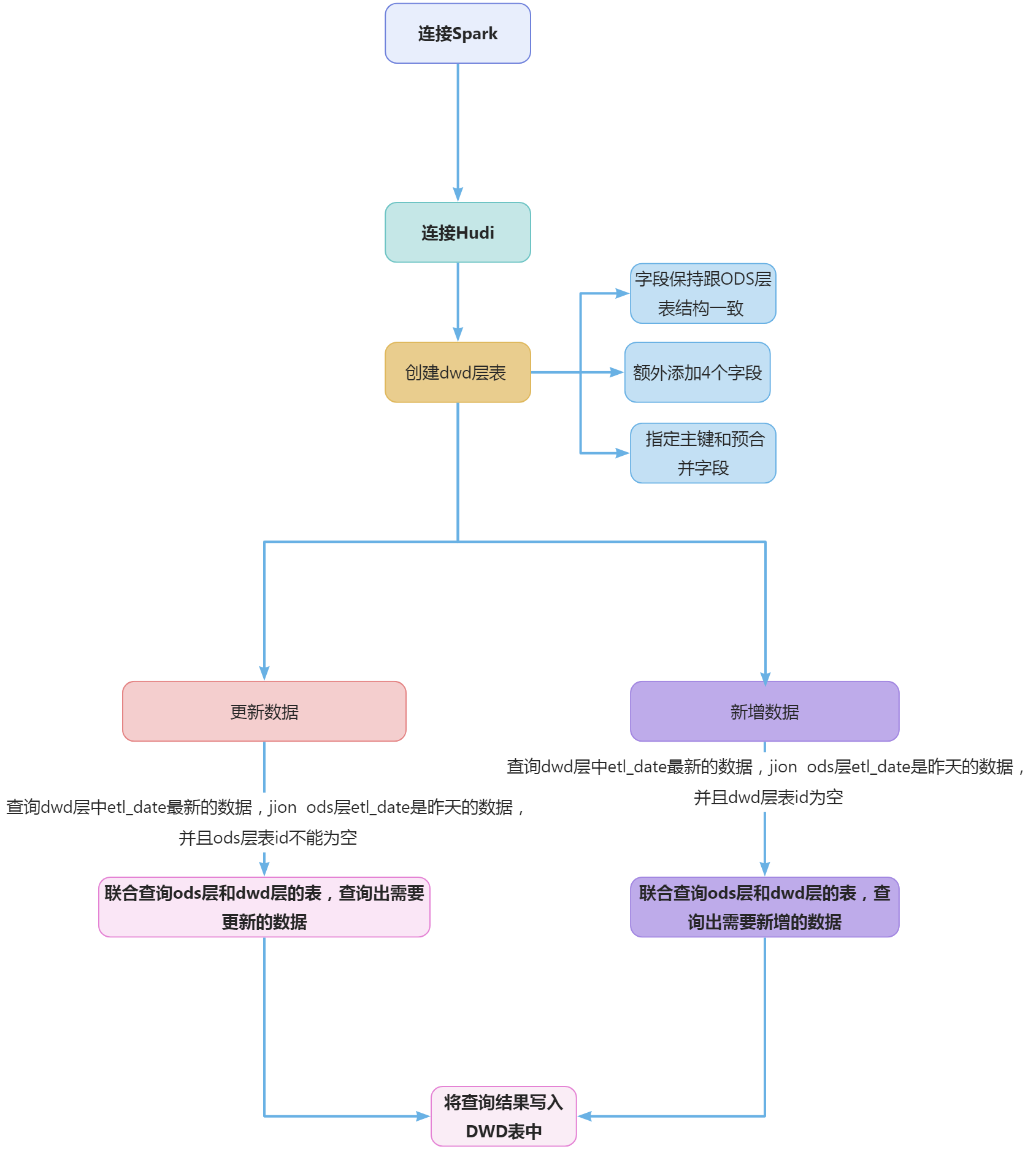
2-3.大数据国赛第2套任务B-子任务三指标计算
任务要求11.1编写job2脚本1.2编写job3脚本1.3编写job4脚本1.4编写azkaban脚本1.5打包上传azkaban脚本1.6执行azkaban脚本任务要求22.1实现流程概要2.2创建DWS层表2.3统计每个用户每天的消费金额2...

大数据国赛培训2023(目录)
2023年全国职业院校技能大赛赛题 2023年全国职业院校技能大赛赛题第02套 2023年全国职业院校技能大赛评分标准(02) 专题1:2023大数据国赛第2套任务A 1-1.linux相关命令入门 1-2.Hadoop分布式安...
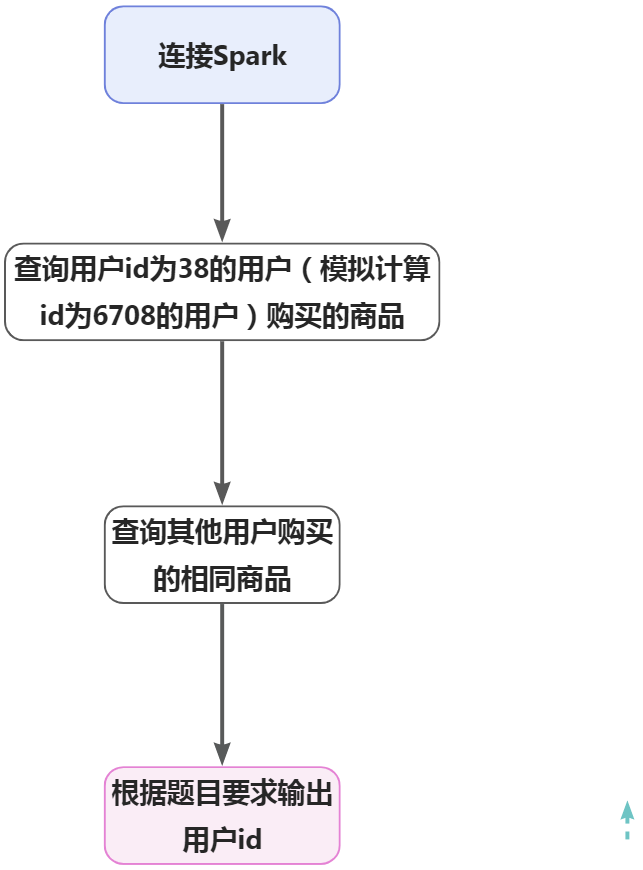
3-1.大数据国赛第2套任务C-子任务一特征工程
任务要求11.1实现思路1.2连接Spark1.3查询用户id为38的用户购买的商品id1.4查询其他用户购买的相同商品数量1.5按格式输出结果任务要求22.1实现思路2.2连接Spark2.3实现方式一2.4实现方式二 任...
1-1.linux相关命令入门
实验环境实验准备实验内容一、环境变量和脚本相关命令二、文件和目录操作命令三、文本编辑器命令四、网络相关命令五、软件包管理命令 实验环境Ubuntu 18.04 64位GNU bash 版本 4.4.20实验环境S...

3-2.大数据国赛第2套任务C-子任务二推荐系统
任务要求11.1实现思路1.2连接Spark1.3实现方式一1.4实现方式二 任务要求1根据子任务一的结果,计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户id(只考虑他俩购买过多少种相...
