

剔除订单信息表与订单详细信息表中用户id与商品id不存在现有的维表中的记录,同时建议多利用缓存并充分考虑并行度来优化代码,达到更快的计算效果。
根据Hudi的dwd_ds_hudi库中相关表或MySQL中shtd_store中相关表(order_detail、sku_info),计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户(只考虑他俩购买过多少种相同的商品,不考虑相同的商品买了多少次),将10位用户id进行输出,若与多个用户购买的商品种类相同,则输出结果按照用户id升序排序,输出格式如下,将结果截图粘贴至客户端桌面【Release任务C提交结果.docx】中对应的任务序号下;
结果格式如下:
——————-相同种类前10的id结果展示为:——————–
1,2,901,4,5,21,32,91,14,52
—
—
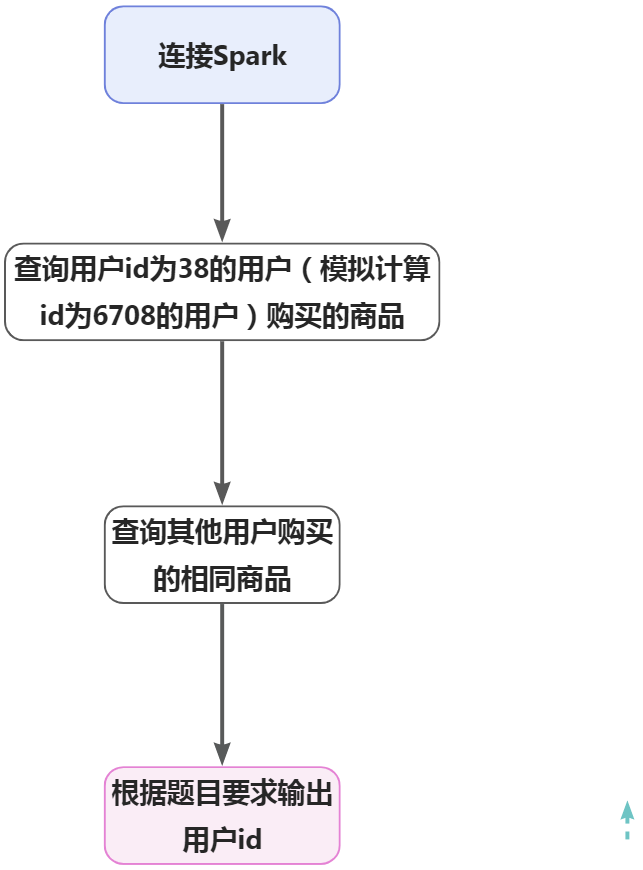
在Linux终端执行如下命令,连接spark shell
spark-shell --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
—
用user_id为38的用户,模拟计算id为6708的用户,并计算所购买相同商品种类,sku_id为商品的id,把分区设置成20,提高并行度。
spark.sql(
"""
|select distinct `user_id`, `sku_id`
|from `dwd_ds_hudi`.`fact_order_info` a
|left join `dwd_ds_hudi`.`fact_order_detail` b
| on a.id=b.order_id
| where `user_id`='38'
|""".stripMargin).repartition(20).createOrReplaceTempView("tmp1")
—
计算其他用户购买的商品种类,商品种类在id为38(模拟6708用户)购买的商品种类之内的种类数。
spark.sql(
"""select `user_id`, count( distinct `sku_id`) as ct
| from `dwd_ds_hudi`.`fact_order_info` a
| left join `dwd_ds_hudi`.`fact_order_detail` b
| on a.id=b.order_id
| where `sku_id` in(select `sku_id` from tmp1) and `user_id`<>'38' group by `user_id`
|""".stripMargin).repartition(20).createOrReplaceTempView("tmp2")
按购买的种类数降序排名,若与多个用户购买的商品种类相同,则输出结果按照用户id升序排序
spark.sql(
"""select c.`user_id`,row_number() over(order by ct desc ,`user_id`) rn from
|(
| select `user_id`, count( distinct `sku_id`) as ct
| from `dwd_ds_hudi`.`fact_order_info` a
| left join `dwd_ds_hudi`.`fact_order_detail` b
| on a.id=b.order_id
| where `sku_id` in(select `sku_id` from tmp1) and `user_id`<>'38' group by `user_id`
| ) c
|""".stripMargin).repartition(20).createOrReplaceTempView("tmp2")
—
根据任务要求,输出的结果格式如下: ——————-相同种类前10的id结果展示为:——————– 1,2,901,4,5,21,32,91,14,52 第一行要显示“——————-相同种类前10的id结果展示为:——————–”,第二行显示前10的用户的id用逗号分割。第一行相当于直接输出提示符,第二行要把前10的id连接成一个字符串,那么可以通过union all来合并两个字符串字段,那么两个字符串的字段名必须要一样。 通过sql先输出第一行试试
spark.sql(
"""select "-------------------相同种类前10的id结果展示为:--------------------" as output
""".stripMargin).repartition(20).show(truncate=false)
由于查询出来的用户id是多行,根据要求需要在一行里显示,那么我们需要将查询出来的多行转换成一行。我们可以将前10的每个用户转换成10列,每个用户所在的列为自己的id,其他列为空,然后依次union all其他用户。
spark.sql(
"""select user_id as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=1
|union all
|select '' as n1,user_id as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=2
|union all
|select '' as n1,'' as n2,user_id as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=3
|union all
|select '' as n1,'' as n2,'' as n3,user_id as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=4
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,user_id as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=5
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,user_id as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=6
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,user_id as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=7
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,user_id as n8,'' as n9, '' as n10 from tmp2 where rn=8
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,user_id as n9, '' as n10 from tmp2 where rn=9
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, user_id as n10 from tmp2 where rn=10
|""".stripMargin).repartition(20).show(truncate=false)
然后再取出每一列的最大值,就可以将多列合并成一列了。由于每一行的对应列都只有自己的id,要么有要么为空,所以不会对结果造成影响。
spark.sql(
"""select concat(max(n1),',',max(n2),',',max(n3),',',max(n4),',',max(n5),',',max(n6),',',max(n7),',',max(n8),',',max(n9),',',max(n10)) as output from
|(select user_id as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=1
|union all
|select '' as n1,user_id as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=2
|union all
|select '' as n1,'' as n2,user_id as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=3
|union all
|select '' as n1,'' as n2,'' as n3,user_id as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=4
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,user_id as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=5
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,user_id as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=6
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,user_id as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=7
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,user_id as n8,'' as n9, '' as n10 from tmp2 where rn=8
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,user_id as n9, '' as n10 from tmp2 where rn=9
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, user_id as n10 from tmp2 where rn=10) a
|""".stripMargin).repartition(20).show(truncate=false)
综上操作,最终输出结果就可以通过如下方式显示
spark.sql(
"""select concat(max(n1),',',max(n2),',',max(n3),',',max(n4),',',max(n5),',',max(n6),',',max(n7),',',max(n8),',',max(n9),',',max(n10)) as output from
|(select user_id as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=1
|union all
|select '' as n1,user_id as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=2
|union all
|select '' as n1,'' as n2,user_id as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=3
|union all
|select '' as n1,'' as n2,'' as n3,user_id as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=4
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,user_id as n5,'' as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=5
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,user_id as n6,'' as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=6
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,user_id as n7,'' as n8,'' as n9, '' as n10 from tmp2 where rn=7
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,user_id as n8,'' as n9, '' as n10 from tmp2 where rn=8
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,user_id as n9, '' as n10 from tmp2 where rn=9
|union all
|select '' as n1,'' as n2,'' as n3,'' as n4,'' as n5,'' as n6,'' as n7,'' as n8,'' as n9, user_id as n10 from tmp2 where rn=10) a
| union all
|select '-------------------相同种类前10的id结果展示为:--------------------' as output
|""".stripMargin).repartition(20).show(truncate=false)
根据Hudi的dwd_ds_hudi库中相关表或MySQL中shtd_store中相关商品表(sku_info),获取id、spu_id、price、weight、tm_id、category3_id 这六个字段并进行数据预处理,对price、weight进行规范化(StandardScaler)处理,对spu_id、tm_id、category3_id进行one-hot编码处理(若该商品属于该品牌则置为1,否则置为0),并按照id进行升序排序,在集群中输出第一条数据前10列(无需展示字段名),将结果截图粘贴至客户端桌面【Release任务C提交结果.docx】中对应的任务序号下。
| 字段 | 类型 | 中文含义 | 备注 |
|---|---|---|---|
| id | double | 主键 | |
| price | double | 价格 | |
| weight | double | 重量 | |
| spu_id#1 | double | spu_id 1 | 若属于该spu_id,则内容为1否则为0 |
| spu_id#2 | double | spu_id 2 | 若属于该spu_id,则内容为1否则为0 |
| ….. | double | ||
| tm_id#1 | double | 品牌1 | 若属于该品牌,则内容为1否则为0 |
| tm_id#2 | double | 品牌2 | 若属于该品牌,则内容为1否则为0 |
| …… | double | ||
| category3_id#1 | double | 分类级别3 1 | 若属于该分类级别3,则内容为1否则为0 |
| category3_id#2 | double | 分类级别3 2 | 若属于该分类级别3,则内容为1否则为0 |
| …… |
结果格式如下:
——————–第一条数据前10列结果展示为:———————
1.0,0.892346,1.72568,0.0,0.0,0.0,0.0,1.0,0.0,0.0
—
—
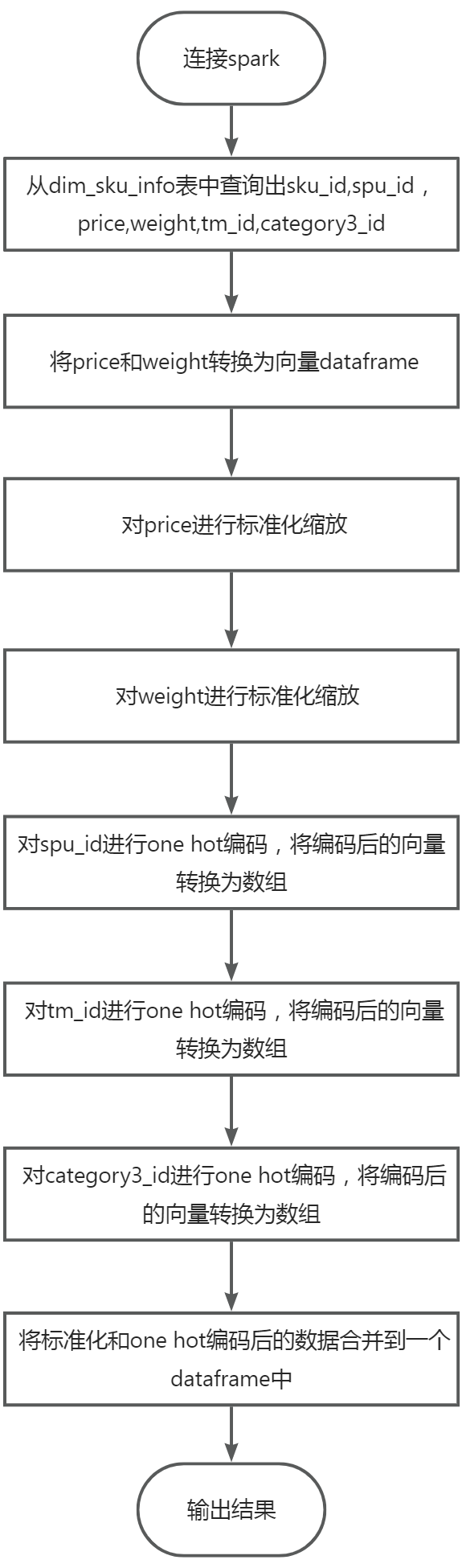
在Linux终端执行如下命令,连接spark shell
spark-shell --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
—
查询需要标准化和one hot编码的数据
从dim_sku_info表中查询出sku_id,spu_id,price,weight,tm_id,category3_id,编写spark sql代码如下:
import spark.implicits._
spark.sql(
"""
|select
| `id` ,
| `spu_id` ,
| `price` ,
| `weight` ,
| `tm_id` ,
| `category3_id`
|from `dwd_ds_hudi`.`dim_sku_info` order by id
|""".stripMargin).createOrReplaceTempView("tmp")
标准化处理price
将price和weight转换为向量dataframe,编写代码如下:
val stdDF= spark.sql("select id,cast(price as double) price,cast(weight as double) weight from tmp order by id").rdd.map(row => (row.getAs[Integer]("id"),
Vectors.dense(row.getAs[Double]("price")),
Vectors.dense(row.getAs[Double]("weight"))
)).toDF("id", "price","weight")
对price进行标准化处理,编写代码如下:
//对price进行标准化
val scaler = new StandardScaler()
.setInputCol("price")
.setOutputCol("stdprice")
.setWithStd(true)
.setWithMean(false)
val scalerModel = scaler.fit(stdDF)
val scaledData = scalerModel.transform(stdDF)
scaledData.show(false)
标准化处理weight
对weight进行标准化,编写代码如下
//对weight进行标准化
val scaler2 = new StandardScaler()
.setInputCol("weight")
.setOutputCol("stdweight")
.setWithStd(true)
.setWithMean(false)
val scalerModel2 = scaler2.fit(scaledData)
val scaledData2 = scalerModel2.transform(scaledData)
scaledData2.show(false)
scaledData2.createOrReplaceTempView("tmp1")
对spu_id进行one-hot编码
查询出id和spu_id数据并转换为dataframe,编写代码如下:
val spu_one_hotDF=spark.sql(
"""
|select distinct id,spu_id from tmp order by id
|""".stripMargin)
对spu_id进行one hot编码
val spu_encoder = new OneHotEncoder()
.setInputCol("spu_id")
.setOutputCol("spu_id_new")
.setDropLast(false)
val spu_encoderModel= spu_encoder.fit(spu_one_hotDF)
val spu_encoderData = spu_encoderModel.transform(spu_one_hotDF)
spu_encoderData.show(false)
将spu_id_new向量转换为数组,定义一个udf函数,将向量转换为数据,获取数组索引为1到最后的数据,编写代码如下:
val toArr: Any => Array[Double] = (input) => {
val arr = input.asInstanceOf[SparseVector].toArray
arr.slice(1, arr.length)
}
val toArrUdf = udf(toArr)
val spu_encoderData2ArrDF = spu_encoderData.withColumn("new_spu_id_encoded",toArrUdf(col("spu_id_new")))
spu_encoderData2ArrDF.show(false)
spu_encoderData2ArrDF.createOrReplaceTempView("tmp2")
对tm_id进行one-hot编码
查询出id和tm_id数据并转换为dataframe,编写代码如下:
val tm_one_hotDF=spark.sql(
"""
|select distinct id,tm_id from tmp order by id
|""".stripMargin)
对tm_id进行one hot编码
val tm_encoder = new OneHotEncoder()
.setInputCol("tm_id")
.setOutputCol("tm_id_new")
.setDropLast(false)
val tm_encoderModel= tm_encoder.fit(tm_one_hotDF)
val tm_encoderData = tm_encoderModel.transform(tm_one_hotDF)
tm_encoderData.show(false)
将tm_id_new向量转换为数组,使用udf函数将向量转换为数据,获取数组索引为1到最后的数据,编写代码如下:
val stm_encoderData2ArrDF = tm_encoderData.withColumn("new_tm_id_encoded",toArrUdf(col("tm_id_new")))
stm_encoderData2ArrDF.show(false)
stm_encoderData2ArrDF.createOrReplaceTempView("tmp3")
对category3_id进行one-hot编码
查询出id和category3_id数据并转换为dataframe,编写代码如下:
val category3_one_hotDF=spark.sql(
"""
|select distinct id,category3_id from tmp order by id
|""".stripMargin)
对category3_id进行one hot编码
val category3_encoder = new OneHotEncoder()
.setInputCol("category3_id")
.setOutputCol("category3_id_new")
.setDropLast(false)
val category3_encoderModel= category3_encoder.fit(category3_one_hotDF)
val category3_encoderData = category3_encoderModel.transform(category3_one_hotDF)
category3_encoderData.show(false)
将category3_id_new向量转换为数组,使用udf函数将向量转换为数据,获取数组索引为1到最后的数据,编写代码如下:
val category3_encoderData2ArrDF = category3_encoderData.withColumn("new_category3_id_encoded",toArrUdf(col("category3_id_new")))
category3_encoderData2ArrDF.show(false)
category3_encoderData2ArrDF.createOrReplaceTempView("tmp4")
将标准化和one hot编码后的数据合并
合并标准化和one hot编码后的数据合并成一个新的表,代码如下:
spark.sql(
"""
|select cast(a.id as Double) as id,
|replace(replace(cast(b.`stdprice` as string),'[',''),']','') as `price`,
|replace(replace(cast(b.`stdweight` as string),'[',''),']','') as `weight`,
|replace(replace(cast(c.`new_spu_id_encoded` as string),'[',''),']','') as `spu_id#`,
|replace(replace(cast(d.`new_tm_id_encoded` as string),'[',''),']','') as `tm_id#`,
|replace(replace(cast(e.`new_category3_id_encoded` as string),'[',''),']','') as `category3_id#`
|from
|tmp a
|left join tmp1 b
|on cast(a.id as string)=cast(b.id as string)
|left join tmp2 c
|on cast(a.id as string)=cast(c.id as string)
|left join tmp3 d
|on cast(a.id as string)=cast(d.id as string)
|left join tmp4 e
|on cast(a.id as string)=cast(e.id as string)
|""".stripMargin).createOrReplaceTempView("tmp5")
spark.sql("select * from tmp5 order by id").show(false)
按要求输出结果
输出结果数据中的前10列数据,代码如下:
spark.sql(
"""
|select
|concat(
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[0],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[1],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[2],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[3],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[4],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[5],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[6],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[7],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[8],
|',',
|split(concat(id,',',price,',',weight,',',`spu_id#`,`tm_id#`,`category3_id#`),',')[9]
|) as output
|from tmp5 order by id limit 1
|""".stripMargin).show(false)
—
查询需要标准化和one hot编码的数据
从dim_sku_info表中查询出sku_id,spu_id,price,weight,tm_id,category3_id,编写spark sql代码如下:
import spark.implicits._
val selectedDF = spark.sql("""
| select
| id,
| spu_id,
| price,
| weight,
| tm_id,
| category3_id
| from dwd_ds_hudi.dim_sku_info order by id
""".stripMargin).toDF()
定义price和weight标准化策略
定义price和weight转换成向量和标准化策略,代码如下:
// 数据规范化:将"price"特征列组合成一个特征向量列
val priceAssembler = new VectorAssembler().setInputCols(Array("price")).setOutputCol("price_features")
// 使用标准缩放器,对特征向量进行标准化,将数据规范化(标准化)为标准正态分布(均值为0,标准差为1)
val priceScaler = new StandardScaler().setInputCol("price_features").setOutputCol("scaled_price_features")
val weightAssembler = new VectorAssembler().setInputCols(Array("weight")).setOutputCol("weight_features")
val weightScaler = new StandardScaler().setInputCol("weight_features").setOutputCol("scaled_weight_features")
定义独热编码策略
将spu_id、tm_id、category3_id当做字符串并生成索引,定义spu_id、tm_id、category3_id的独热编码策略,代码如下:
// 独热编码:对分类特征进行独热编码
// 将字符串类型的分类特征转换为数值型的索引
val spuIdIndexer = new StringIndexer().setInputCol("spu_id").setOutputCol("spu_id_index").setHandleInvalid("skip")
val tmIdIndexer = new StringIndexer().setInputCol("tm_id").setOutputCol("tm_id_index").setHandleInvalid("skip")
val category3IdIndexer = new StringIndexer().setInputCol("category3_id").setOutputCol("category3_id_index").setHandleInvalid("skip")
//根据索引生成one-hot编码,将分类特征(通常是字符串类型的标签)转换为稀疏矩阵形式的独热编码。独热编码将每个不同的类别映射为一个二进制向量,只有一个元素为1,表示该类别。
val oneHotEncoder = new OneHotEncoder().setInputCols(Array("spu_id_index", "tm_id_index", "category3_id_index")).setOutputCols(Array("spu_id_encoded", "tm_id_encoded", "category3_id_encoded")).setDropLast(false)
构建管道拟合并转换数据
构建管道:将数据处理和特征处理的步骤组成一个管道,将多个数据处理和机器学习操作按照指定顺序组合成一个流水线的工具 调用setStages 方法接受一个包含各个阶段实例的数组,按照数组中的顺序执行。 使用管道模型进行转换,transform 方法使用拟合后的模型对测试数据进行转换。
// 构建管道:将数据处理和特征处理的步骤组成一个管道,将多个数据处理和机器学习操作按照指定顺序组合成一个流水线的工具
// setStages 方法接受一个包含各个阶段实例的数组,按照数组中的顺序执行。
val pipeline = new Pipeline().setStages(Array(priceAssembler, priceScaler, weightAssembler, weightScaler, spuIdIndexer, tmIdIndexer, category3IdIndexer, oneHotEncoder))
// 拟合管道模型,fit 方法将 Pipeline 应用到训练数据上,拟合模型。
val model = pipeline.fit(selectedDF)
// 使用管道模型进行转换,transform 方法使用拟合后的模型对测试数据进行转换。
val transformedDF = model.transform(selectedDF)
transformedDF.show(false)
将向量转换为数组
定义udf函数,将spu_id、tm_id、category3_id独热编码后的稀疏向量转换为数组
val toArr: Any => Array[Double] = _.asInstanceOf[SparseVector].toArray
val toArrUdf = udf(toArr)
定义udf函数,将price、weight标准化处理后的稠密向量转换为数组
val toArr2: Any => Array[Double] = _.asInstanceOf[DenseVector].toArray
val toArrUdf2 = udf(toArr2)
将向量转换为数组dataframe
val vector2arrDF = transformedDF.withColumn("new_scaled_price",toArrUdf2(col("scaled_price_features"))).withColumn("new_scaled_weight",toArrUdf2(col("scaled_weight_features"))).withColumn("new_spu_id_encoded",toArrUdf(col("spu_id_encoded"))).withColumn("new_tm_id_encoded",toArrUdf(col("tm_id_encoded"))).withColumn("new_category3_id_encoded",toArrUdf(col("category3_id_encoded")))
vector2arrDF.show(false)
获取转换成数组的数据生成新的dataframe
val resultDF = vector2arrDF.select("id", "new_scaled_price", "new_scaled_weight", "spu_id_index", "tm_id_index", "category3_id_index", "new_spu_id_encoded", "new_tm_id_encoded", "new_category3_id_encoded")
resultDF.show(false)
将数组dataframe转换成多列dataframe
将price、weight数组列转换成多列dataframe
val priceWeightDF = resultDF.select($"id", $"new_scaled_price"(0).alias(s"price"), $"new_scaled_weight"(0).alias(s"weight"))
将spu_id数组列转换成多列dataframe
val spuDF = resultDF.select($"id" +: (1 until resultDF.select("spu_id_index").distinct().count().toInt + 1).map(i => $"new_spu_id_encoded"(i-1).alias(s"spu_id#$i")): _*).withColumnRenamed("id", "id2")
将tm_id数组列转换成多列dataframe
val tmDF = resultDF.select($"id" +: (1 until resultDF.select("tm_id_index").distinct().count().toInt + 1).map(i => $"new_tm_id_encoded"(i-1).alias(s"tm_id#$i")): _*).withColumnRenamed("id", "id2")
将category3_id数组列转换成多列dataframe
val category3DF = resultDF.select($"id" +: (1 until resultDF.select("category3_id_index").distinct().count().toInt + 1).map(i => $"new_category3_id_encoded"(i-1).alias(s"category3_id#$i")): _*).withColumnRenamed("id", "id2")
合并标准化和独热编码处理后的dataframe数据
var resDF = priceWeightDF.join(spuDF, priceWeightDF("id") === spuDF("id2"), "left_outer").drop("id2")
resDF = resDF.join(tmDF, resDF("id") === tmDF("id2"), "left_outer").drop("id2")
resDF = resDF.join(category3DF, resDF("id") === category3DF("id2"), "left_outer").drop("id2")
按要求输出结果
import org.apache.spark.sql.functions._
resDF.withColumn("fullData", concat($"id", lit(", "), $"price", lit(", "), $"weight", lit(", "), $"spu_id#1", lit(", "), $"spu_id#2", lit(", "), $"spu_id#3", lit(", "), $"spu_id#4", lit(", "), $"spu_id#5", lit(", "), $"spu_id#6", lit(", "), $"spu_id#7")).select("fullData").show(1, false)
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。












暂无评论内容