

大数据 第2页
排序

3-2.大数据国赛第2套任务C-子任务二推荐系统
任务要求11.1实现思路1.2连接Spark1.3实现方式一1.4实现方式二 任务要求1根据子任务一的结果,计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户id(只考虑他俩购买过多少种相...

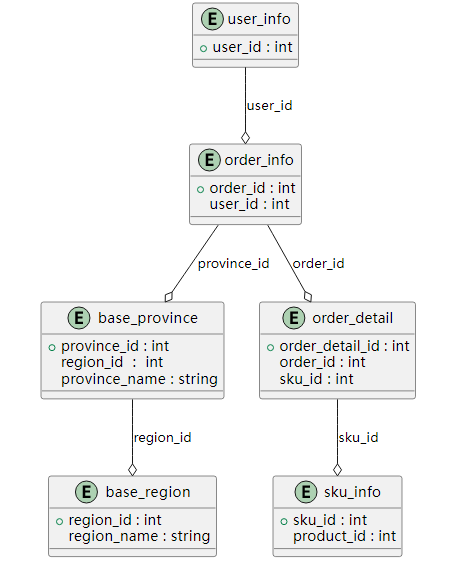
在Spark中实现增量合并(upsert/merge实现)
通常会将大量数据抽取到Hadoop分布式文件系统(HDFS)中进行分析。通常情况下,我们需要用新的变化定期更新这些数据。很长一段时间以来,实现这一目标的最常见方法是使用Apache Hive增量地将新的...
4.5 Scala集合:Stream流
什么是Stream流?根据Scala文档,流是类似于列表的数据结构,只是流的元素是惰性计算机制。因此,可以拥有无限长的流!Stream(流)与List类似,但是它是延迟计算的,所以可以非常非常长。// 创建...
5-1.大数据国赛数据可视化-用柱状图展示各省份消费额的中位数
实验环境实验准备实验内容一、下载安装vue cli二、创建vue.js项目三、编辑App.vue添加MyCharts组件四、写出MyCharts数据可视化组件模板代码五、在模板里添加处理数据的逻辑代码 实验环境Ubun...
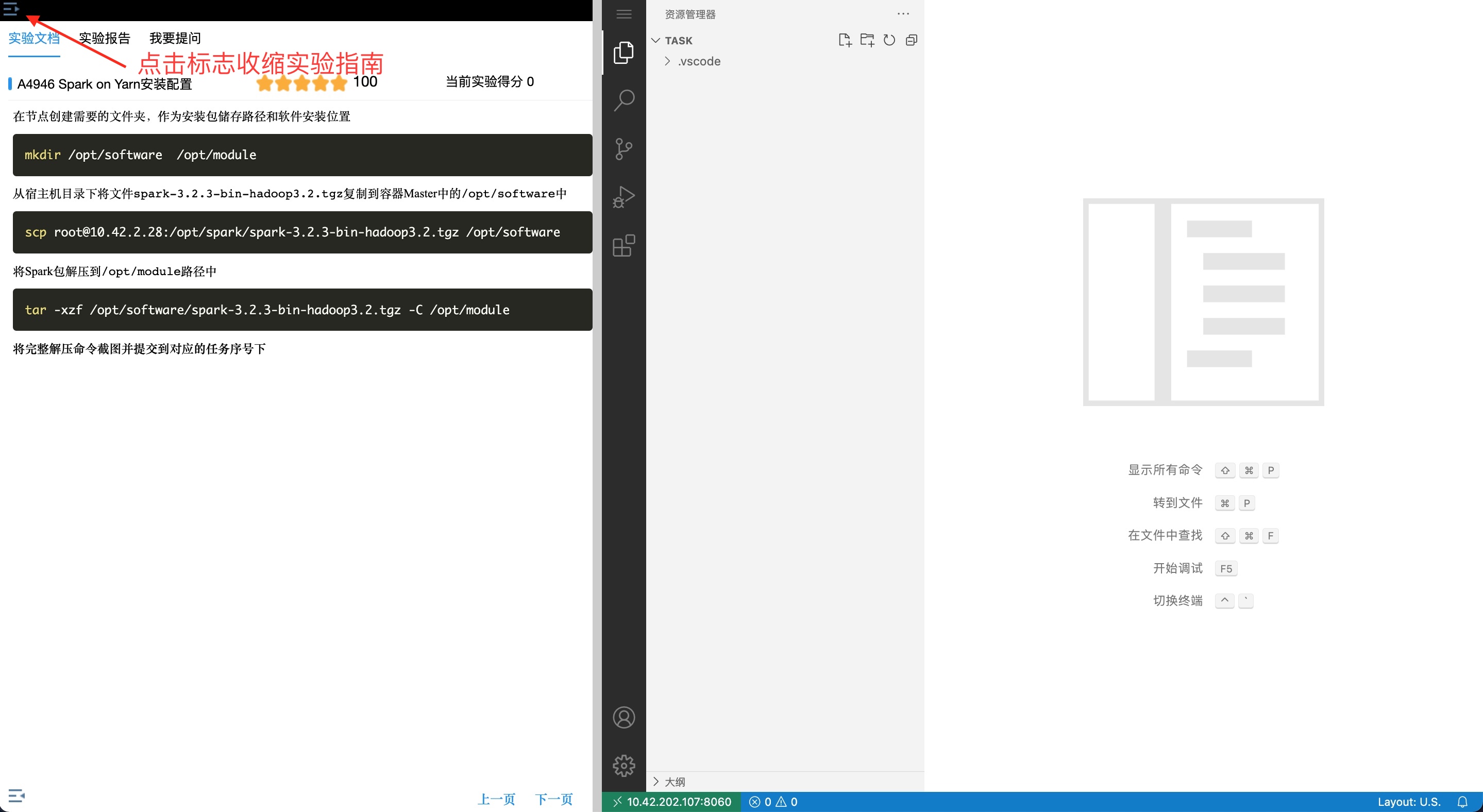
2-1.大数据国赛第2套任务B-子任务一数据抽取
MySQL表结构分析表结构分析user. _info表sku_ _info表base. _province表base_ region表order_ info表order_ detail表任务要求11.1实现流程概要1.2任务分解任务要求22.1创建ODS层表2.2创建MySQL...
4.3 Scala集合:Map
Map是一个key-value 对的集合。在其它语言中,它被称为词典、关联数组、或HashMap。这是一个根据key查找value的高效的数据结构。下面的代码段演示了怎样创建和使用一个Map:val capitals = Map(...

4-2.Flink快速入门
api流程图批处理wordcount流处理wordcount集合sourceKafka SourceKafka SinkRedis Sink api流程图批处理wordcount在src/main/scala/org/example目录下新建WordCount.scala文件,编写批处理代...
2024年重庆甘肃安徽等省职业院校技能大赛_大数据应用开发样题解析-模块C:实时数据处理-任务一:实时数据清洗
环境说明Flink 任务在Yarn 上用per job 模式(即Job 分离模式,不采用Session 模式),方便Yarn 回收资源;建议使用gson 解析json 数据。任务描述编写Java 工程代码,使用Flink 消费Kafka 中Top...
9.1 数值类型简介
在Scala中,所有的数值类型都是对象,包括Byte、Char、Double、Float、Int、Long和Short。这七个数值类型继承自AnyVal trait。它们的取值范围与Java一样:数据类型描述大小最小值最大值Char无符...
2-2.大数据国赛第2套任务B-子任务二数据清洗
任务要求11.1实现流程概要1.2任务分解任务要求22.1创建表2.2按id更新数据2.3按id插入数据2.4查询数据任务要求33.1创建表3.2按Id更新数据3.3按ld插入数据3.4查询数据任务要求44.1创建表4.2按Id更...
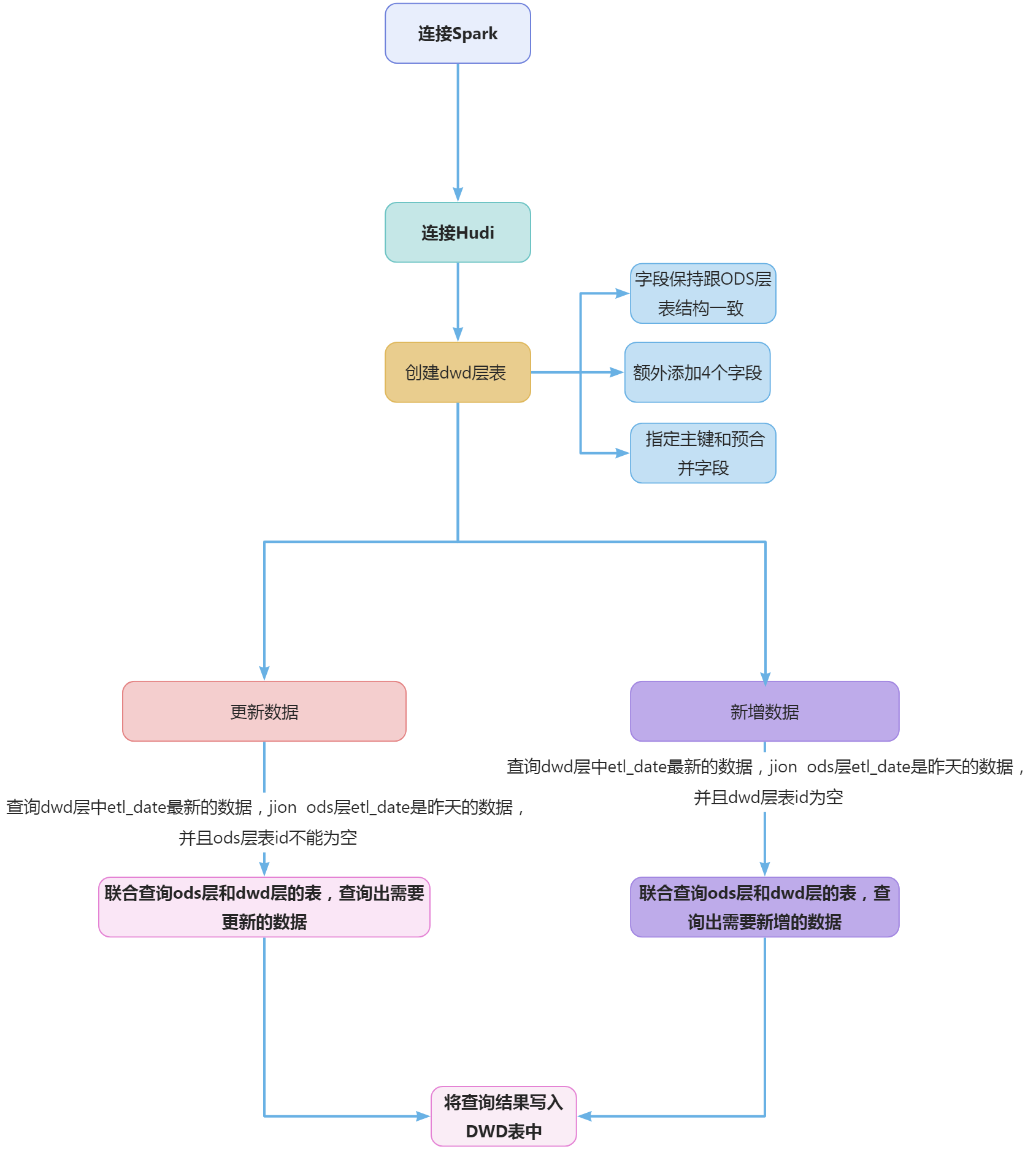
7.5 样例类(case class)
Scala中提供了一种特殊的类,用case class进行声明,中文也可以称作“样例类”。样例类是一种特殊的类,经过优化以用于模式匹配。样例类类似于常规类,带有一个case 修饰符的类,在构建不可变类...
1-8.Hudi安装配置
实验环境实验准备实验内容一、下载所需安装包二、安装配置Maven运行环境三、使用maven对Hudi进行构建四、安装配置Spark运行环境五、启动spark-shell运行案例 实验环境Ubuntu 18.04Spark 3.2....

1.4 使用IDEA开发Scala应用程序
接下来,我们就可以开发第一个Scala程序“HelloWorld”了。本节包括如下内容:创建Scala项目创建Scala应用程序注意:确保已经安装好了JDK 8+。 创建Scala项目首先我们在IntelliJ IDEA中创建一...
5-2.大数据国赛数据可视化-用玫瑰图展示各地区消费能力
实验环境实验准备实验内容一、下载安装vue cli二、创建vue.js项目三、编辑App.vue添加MyCharts组件四、写出MyCharts数据可视化组件模板代码五、在模板里添加处理数据的逻辑代码 实验环境Ubun...
8.3 使用正则表达式处理字符串
字符串中正则表达式模式匹配通过在String上调用.r方法来创建一个scala.util.matching.Regex对象,然后在findFirstIn中使用该模式来查找一个匹配,在findAllIn中使用该模式来查找所有的匹配。 ...

1.3 使用IntelliJ IDEA集成开发环境
在本节中,我们将使用流行的IntelliJ IDEA来展示如何设置编写Scala代码的开发环境。本节包括如下内容:下载IntelliJ IDEA安装IntelliJ IDEA安装Scala插件注意:确保已经安装好了JDK 8+。 下载I...
