


在src/main/scala/org/example目录下新建WordCount.scala文件,编写批处理代码实现单词计数,代码如下:
package org.example
import org.apache.flink.api.scala._
import org.apache.flink.api.scala.{AggregateDataSet, DataSet, ExecutionEnvironment}
object WordCount {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val inputPath="/rgsoft/Desktop/Study/task/src/main/resources/a.txt"
val inputDS: DataSet[String] = env.readTextFile(inputPath)
val wordCountDS: AggregateDataSet[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
wordCountDS.print()
}
}
运行批处理代码

在src/main/scala/org/example目录下新建StreamWordCount.scala文件,编写代码从socket读取流,实现单词计数,代码如下:
package org.example
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textDStream:DataStream[String]= env.socketTextStream("localhost", 7777)
val dataStream : DataStream[(String, Int)] = textDStream.flatMap(_.split("s")).map((_,1)).keyBy(0).sum(1)
dataStream.print()
env.execute("Socket stream word count")
}
}
在终端执行如下命令,启动socket
nc -lp 7777
启动流处理代码

在socket中输入测试数据
hello word
hello rgsoft
在src/main/scala/org/example目录下新建StreamApiDemo.scala文件,编写代码从传感器集合创建流,代码如下:
package org.example
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}
// 定义样例类,传感器 id,时间戳,温度
case class SensorReading(id: String, timestamp: Long, temperature: Double)
object StreamApiDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromCollection(List(
SensorReading("sensor_1", 1547718199, 35.80018327300259),
SensorReading("sensor_6", 1547718201, 15.402984393403084),
SensorReading("sensor_7", 1547718202, 6.720945201171228),
SensorReading("sensor_10", 1547718205, 38.101067604893444)
))
stream.print("stream:")
env.execute("SteamApiDemo")
}
}
运行流处理代码
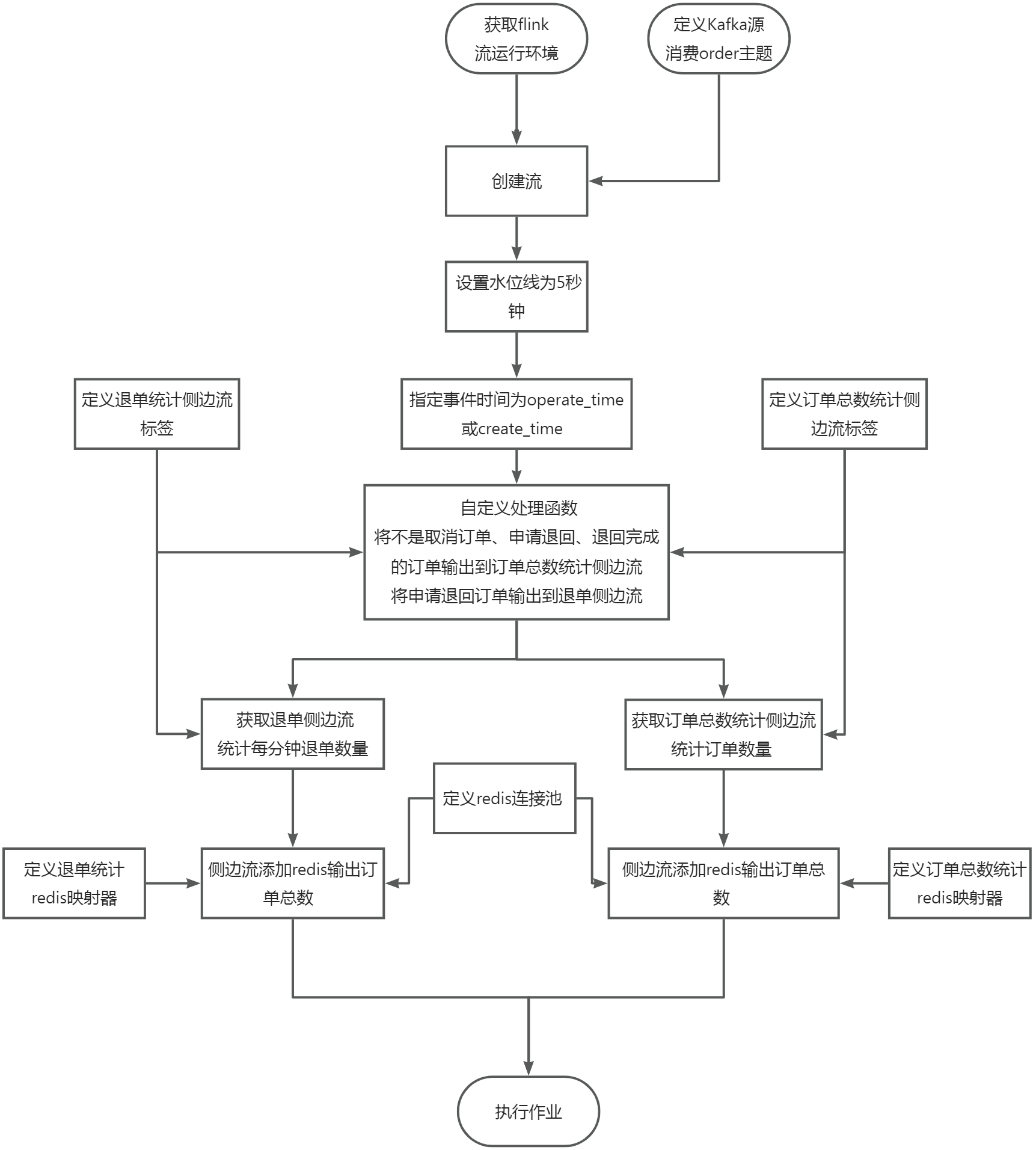
在src/main/scala/org/example目录下新建StreamApiDemo1.scala文件,编写代码从kafka创建流,代码如下:
package org.example
import org.apache.flink.api.common.eventtime.WatermarkStrategy
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}
object StreamApiDemo1 {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val kafkaSource = KafkaSource.builder()
.setTopics("order")
.setGroupId("order1")
.setBootstrapServers("localhost:9092")
.setValueOnlyDeserializer(new SimpleStringSchema()).build()
val stream = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks[String], "Kafka Source")
stream.print("stream:").setParallelism(1)
env.execute("SteamApiDemo1")
}
}
在终端执行如下命令,启动zookeeper和kafka
zkServer.sh start
/opt/kafka_2.12-2.4.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.4.1/config/server.properties
创建order主题
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 4 --topic order
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --zookeeper localhost:2181 --list
运行流处理代码

在终端执行如下命令,启动kafka生产者
/opt/kafka_2.12-2.4.1/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic order
向topic中发送测试数据
hello word
hello rgsoft
在src/main/scala/org/example目录下新建KafkaSinkDemo.scala文件,编写代码将流处理后的数据写入kafka,代码如下:
package org.example
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.connector.kafka.sink.KafkaSink
import org.apache.kafka.clients.producer.KafkaProducer
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.connector.base.DeliveryGuarantee
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
object KafkaSinkDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textDStream:DataStream[String]= env.socketTextStream("localhost", 7777)
val dataStream : DataStream[(String, Int)] = textDStream.flatMap(_.split("s")).map((_,1)).keyBy(0).sum(1)
dataStream.print()
val kafkaRecordSerializationSchema = KafkaRecordSerializationSchema.builder().setTopic("test").setValueSerializationSchema(new SimpleStringSchema()).build()
val kafkaSink = KafkaSink.builder().setBootstrapServers("localhost:9092")
.setRecordSerializer(kafkaRecordSerializationSchema)
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build()
dataStream.map(i => i._1 + "," +i._2).sinkTo(kafkaSink)
env.execute("KafkaSinkDemo")
}
}
在终端执行如下命令,启动socket
nc -lp 7777
创建写出数据的topic
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 4 --topic test
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --zookeeper localhost:2181 --list
启动流处理代码
在socket中输入测试数据
hello word
hello rgsoft
启动kafka消费者,查看结果数据
/opt/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
在src/main/scala/org/example目录下新建RedisSink.scala文件,编写代码将流处理后的数据写入redis,代码如下:
package org.example
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors
import connectors.redis.common.mapper.RedisCommandDescription
import connectors.redis.common.mapper.RedisMapper
import connectors.redis.common.mapper.RedisCommand
object RedisSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val textDStream:DataStream[String]= env.socketTextStream("localhost", 7777)
val dataStream : DataStream[(String, Int)] = textDStream.flatMap(_.split("s")).map((_,1)).keyBy(0).sum(1)
dataStream.print()
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
dataStream.addSink(new connectors.redis.RedisSink[(String, Int)](conf, new MyRedisMapper()))
env.execute("RedisSink demo")
}
// 实现RedisMapper接口
class MyRedisMapper extends RedisMapper[(String, Int)] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.SET)
override def getKeyFromData(t: (String, Int)): String = t._1
override def getValueFromData(t: (String, Int)): String = String.valueOf(t._2)
}
}
启动redis
redis-server &
运行流处理代码
在socket中输入测试数据
hello word
hello rgsoft
打开redis终端执行如下命令,查看结果
redis-cli
keys *
get hello
© 版权声明
本站网络名称:
知趣
本站永久网址:
https://www.qubaa.top
网站侵权说明:
本网站的文章部分内容可能来源于网络,仅供大家学习与参考,如有侵权,请联系站长删除处理。
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。
THE END










暂无评论内容