

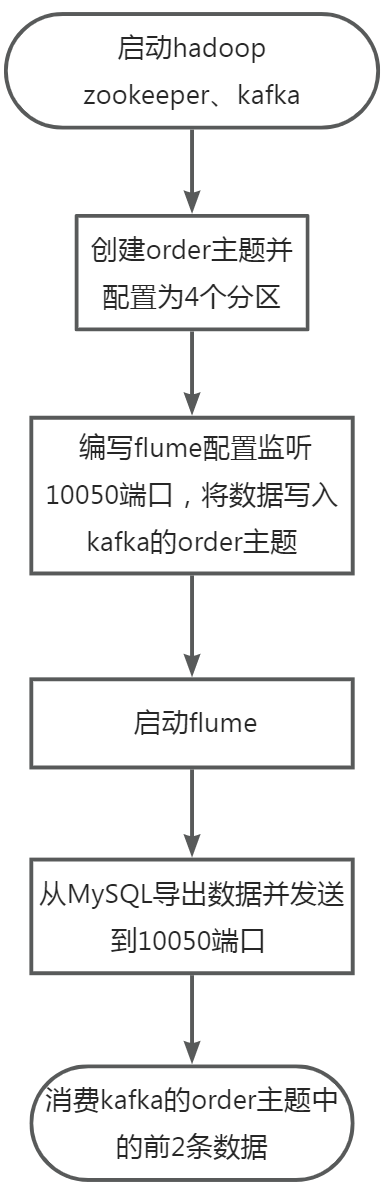
在主节点使用Flume采集实时数据生成器10050端口的socket数据,将数据存入到Kafka的Topic中(Topic名称为order,分区数为4),使用Kafka自带的消费者消费order(Topic)中的数据,将前2条数据的结果截图粘贴至客户端桌面【Release任务D提交结果.docx】中对应的任务序号下;
—
—
在终端执行如下命令,启动Hadoop、Zookeeper、Kafka环境
/opt/hadoop-3.2.4/sbin/start-all.sh
zkServer.sh start
/opt/kafka_2.12-2.4.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.4.1/config/server.properties
—
在终端执行如下命令,利用kafka的命令行工具创建order主题并设置为4个分区
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 4 --topic order
创建后查看一下主题是否创建成功
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --zookeeper localhost:2181 --list
—
新建getstreamingdata10050.conf文件,编写flume配置实现监听10050端口,将收到的数据发送的kafka的order主题,代码如下:
# 给这个代理上的组件命名
# 定义一个名为 r1 的数据源
a1.sources = r1
# 定义一个名为 k1 的数据汇
a1.sinks = k1
# 定义一个名为 c1 的通道
a1.channels = c1
# 描述/配置数据源
# 数据源的类型为 netcat
a1.sources.r1.type = netcat
# 数据源绑定到本地主机
a1.sources.r1.bind = localhost
# 数据源监听端口为 10050
a1.sources.r1.port = 10050
# 描述 KafkaSink 数据汇
# 数据汇的类型为 KafkaSink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
# Kafka 服务器的地址
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
# Kafka 主题的名称为 order
a1.sinks.k1.kafka.topic = order
# 使用一个在内存中缓冲事件的通道
# 通道的类型为 memory
a1.channels.c1.type = memory
# 通道的容量为 1000
a1.channels.c1.capacity = 1000
# 通道的事务容量为 100
a1.channels.c1.transactionCapacity = 100
# 将数据源和数据汇绑定到通道
# 将数据源 r1 绑定到通道 c1
a1.sources.r1.channels = c1
# 将数据汇 k1 绑定到通道 c1
a1.sinks.k1.channel = c1
在Apache Flume中,通道(Channel)是用于在数据源和数据汇之间传递事件的缓冲区。通道容量(Channel Capacity)和事务容量(Transaction Capacity)是两个与通道相关的重要概念。
-
通道容量(Channel Capacity):
-
通道容量指的是通道能够存储的事件数量的上限。
-
当通道容量已满时,如果继续产生事件,数据源可能需要等待通道有足够的空间来存储事件,这可能导致数据源的阻塞。
-
通道容量的大小通常需要根据系统的吞吐量和性能需求进行调整。较大的容量可以处理更多的事件,但也会占用更多的内存。
-
-
事务容量(Transaction Capacity):
-
事务容量是指在一个事务中可以处理的事件数量。
-
Flume 通道支持事务,以确保在事件从数据源传递到数据汇的过程中的一致性和可靠性。
-
事务容量定义了每个事务中允许处理的事件数量,当事务容量达到上限时,将触发事务的提交。
-
较大的事务容量可能导致更大的事务,但也可能在事务中包含更多的事件,从而提高吞吐量。
-
—
在终端执行如下命令,使用编写的配置文件启动flume监听10050端口,并把event数据写入到kafka中。
/opt/apache-flume-1.9.0-bin/bin/flume-ng agent -c /opt/apache-flume-1.9.0-bin/conf/ -n a1 -f /rgsoft/Desktop/Study/task/getstreamingdata10050.conf -Dflume.root.logger=INFO,console
—
新建order_data_generator.sh文件,编写脚本实现将MySQL中的order_info表的数据导出到csv文件,然后将csv文件中的内容通过socket发送到10050端口。代码如下:
mysql -uroot1 -p123456 -e"
SELECT * INTO OUTFILE '/var/lib/mysql-files/order_info.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY 'n'
FROM shtd_store.order_info
"
sudo apt-get update
sudo apt-get install telnet -y
cat /var/lib/mysql-files/order_info.csv |nc localhost 10050
—
在终端执行如下命令,运行数据生成脚本
bash order_data_generator.sh
—
在终端执行如下命令,使用Kafka自带的消费者消费order(Topic)中将前2条数据。
/opt/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic order --max-messages 2
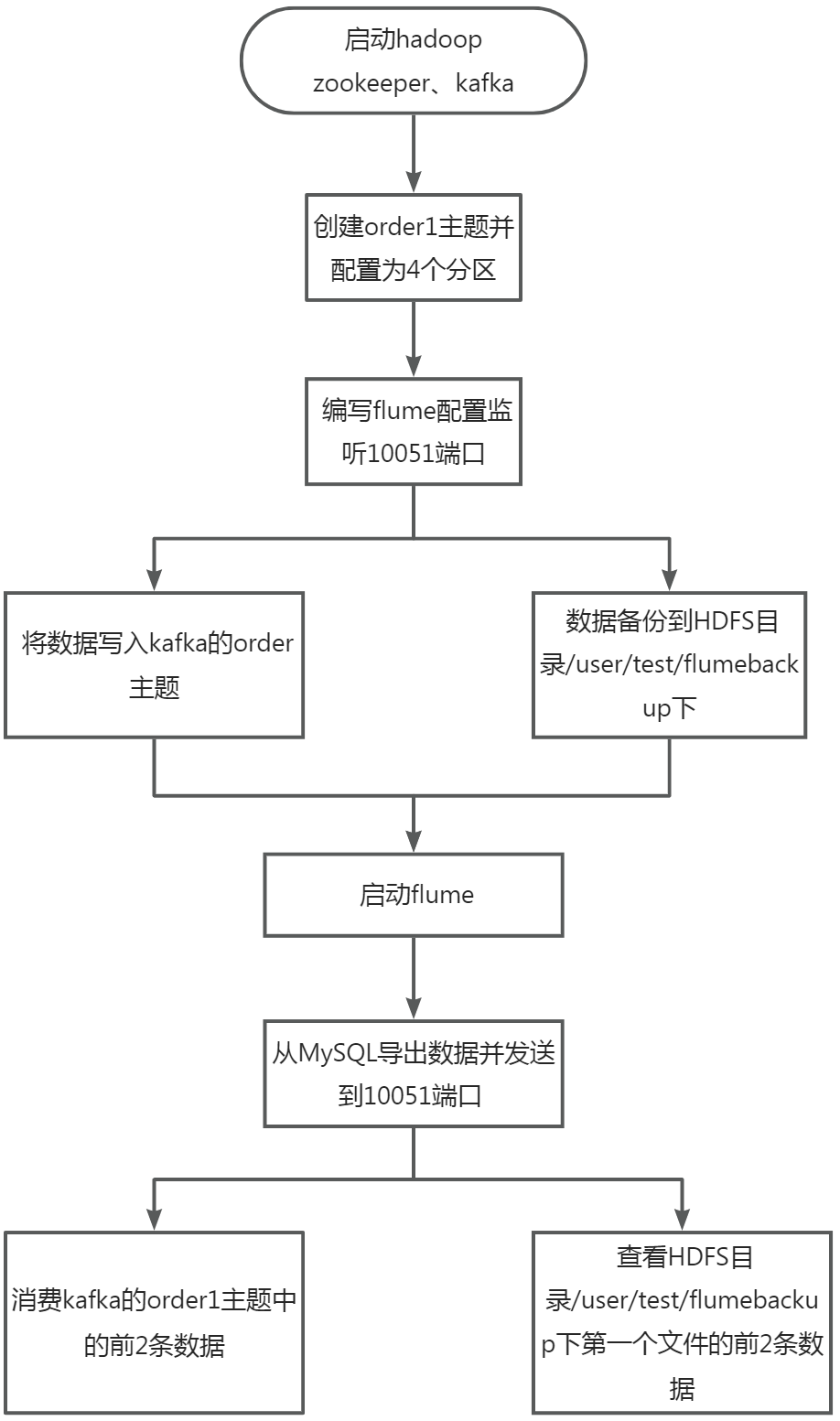
采用多路复用模式,Flume接收数据注入kafka 的同时,将数据备份到HDFS目录/user/test/flumebackup下,将查看备份目录下的第一个文件的前2条数据的命令与结果截图粘贴至客户端桌面【Release任务D提交结果.docx】中对应的任务序号下。
—
—
在终端执行如下命令,启动Hadoop、Zookeeper、Kafka环境
/opt/hadoop-3.2.4/sbin/start-all.sh
zkServer.sh start
/opt/kafka_2.12-2.4.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.12-2.4.1/config/server.properties
—
在终端执行如下命令,利用kafka的命令行工具创建order1主题并设置为4个分区
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 4 --topic order1
创建后查看一下主题是否创建成功
/opt/kafka_2.12-2.4.1/bin/kafka-topics.sh --zookeeper localhost:2181 --list
—
新建mutisinks.conf文件,编写flume配置实现监听10051端口,将收到的数据发送的kafka的order1主题和将数据备份到hdfs的/user/test/flumebackup/目录,代码如下:
# 给这个代理上的组件命名
# 定义一个名为 r1 的数据源
a1.sources = r1
# 定义两个数据汇,分别为 k1 和 k2
a1.sinks = k1 k2
# 定义两个通道,分别为 c1 和 c2
a1.channels = c1 c2
# 描述/配置数据源
# 数据源的类型为 netcat
a1.sources.r1.type = netcat
# 数据源绑定到本地主机
a1.sources.r1.bind = localhost
# 数据源监听端口为 10051
a1.sources.r1.port = 10051
# 描述 HDFS 数据汇
# 数据汇的类型为 HDFS
a1.sinks.k1.type = hdfs
# HDFS 存储路径
a1.sinks.k1.hdfs.path = /user/test/flumebackup/
# HDFS 文件前缀
a1.sinks.k1.hdfs.filePrefix = log-
# 描述 KafkaSink 数据汇
# 数据汇的类型为 KafkaSink
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
# Kafka 服务器的地址
a1.sinks.k2.kafka.bootstrap.servers = localhost:9092
# Kafka 主题的名称为 order1
a1.sinks.k2.kafka.topic = order1
# 文件路径下采用了%Y,系统会以日期创建文件夹
# filePrefix 文件的前缀
# 从临时文件变正式文件时间 s
a1.sinks.k1.hdfs.rollInterval = 10
# 文件大小
#rollSize 定义了在多大的数据量下触发一个滚动(Roll)操作。
#67108864 表示 64 MB,即当写入的数据达到 64 MB 时,会触发一个新的文件滚动,生成一个新的 HDFS 文件
a1.sinks.k1.hdfs.rollSize = 67108864
#rollCount 定义了在多少事件数量下触发一个滚动操作。
#0 表示不基于事件数量触发滚动,仅基于数据量 (rollSize) 触发滚动。
a1.sinks.k1.hdfs.rollCount = 0
#useLocalTimeStamp 决定是否在 HDFS 文件名中使用本地时间戳
#如果设置为 true,则文件名可能包含本地写入时的时间戳,以提供时间戳信息。
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#fileType 定义了写入 HDFS 的文件类型。
#在这里,设置为 DataStream 表示使用流式数据(DataStream)的方式写入文件。这意味着文件会不断地追加新的数据而不会清空文件。
a1.sinks.k1.hdfs.fileType = DataStream
# rollSize这里是以B为单位,这里是64MB
# fileType监听方式是流
# 使用内存中缓冲事件的通道
# 通道 c2 的类型为 memory
a1.channels.c2.type = memory
# 通道 c2 的容量为 1000
a1.channels.c2.capacity = 1000
# 通道 c2 的事务容量为 100
a1.channels.c2.transactionCapacity = 100
# 通道 c1 的类型为 memory
a1.channels.c1.type = memory
# 通道 c1 的容量为 1000
a1.channels.c1.capacity = 1000
# 通道 c1 的事务容量为 100
a1.channels.c1.transactionCapacity = 100
# 将数据源和数据汇绑定到通道
# 将数据源 r1 绑定到通道 c1 和 c2
a1.sources.r1.channels = c1 c2
# 将数据汇 k1 绑定到通道 c1
a1.sinks.k1.channel = c1
# 将数据汇 k2 绑定到通道 c2
a1.sinks.k2.channel = c2
—
在终端执行如下命令,使用编写的配置文件启动flume监听10051端口,并把event数据写入到kafka中和HDFS中。
/opt/apache-flume-1.9.0-bin/bin/flume-ng agent -c /opt/apache-flume-1.9.0-bin/conf/ -n a1 -f /rgsoft/Desktop/Study/task/mutisinks.conf -Dflume.root.logger=INFO,console
—
新建order_data_generator2.sh文件,编写脚本实现将MySQL中的order_info表的数据导出到csv文件,然后将csv文件中的内容通过socket发送到10051端口。代码如下:
mysql -uroot1 -p123456 -e"
SELECT * INTO OUTFILE '/var/lib/mysql-files/order_info.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY ''
LINES TERMINATED BY 'n'
FROM shtd_store.order_info
"
sudo apt-get update
sudo apt-get install telnet -y
cat /var/lib/mysql-files/order_info.csv |nc localhost 10051
—
在终端执行如下命令,运行数据生成脚本
bash order_data_generator2.sh
—
在终端执行如下命令,使用Kafka自带的消费者消费order(Topic)中将前2条数据。
/opt/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic order1 --max-messages 2
在终端执行如下命令,查看hdfs上/user/test/flumebackup是否有新文件生成,并查看新文件中前两行数据
hadoop dfs -ls /user/test/flumebackup/
hadoop dfs -head /user/test/flumebackup/log-.1702109618956
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。











暂无评论内容