

-
Ubuntu 18.04
-
Spark 3.2.3
-
Hudi 0.14.0
1、 进入实验环境后, 点击左上角收缩实验指南 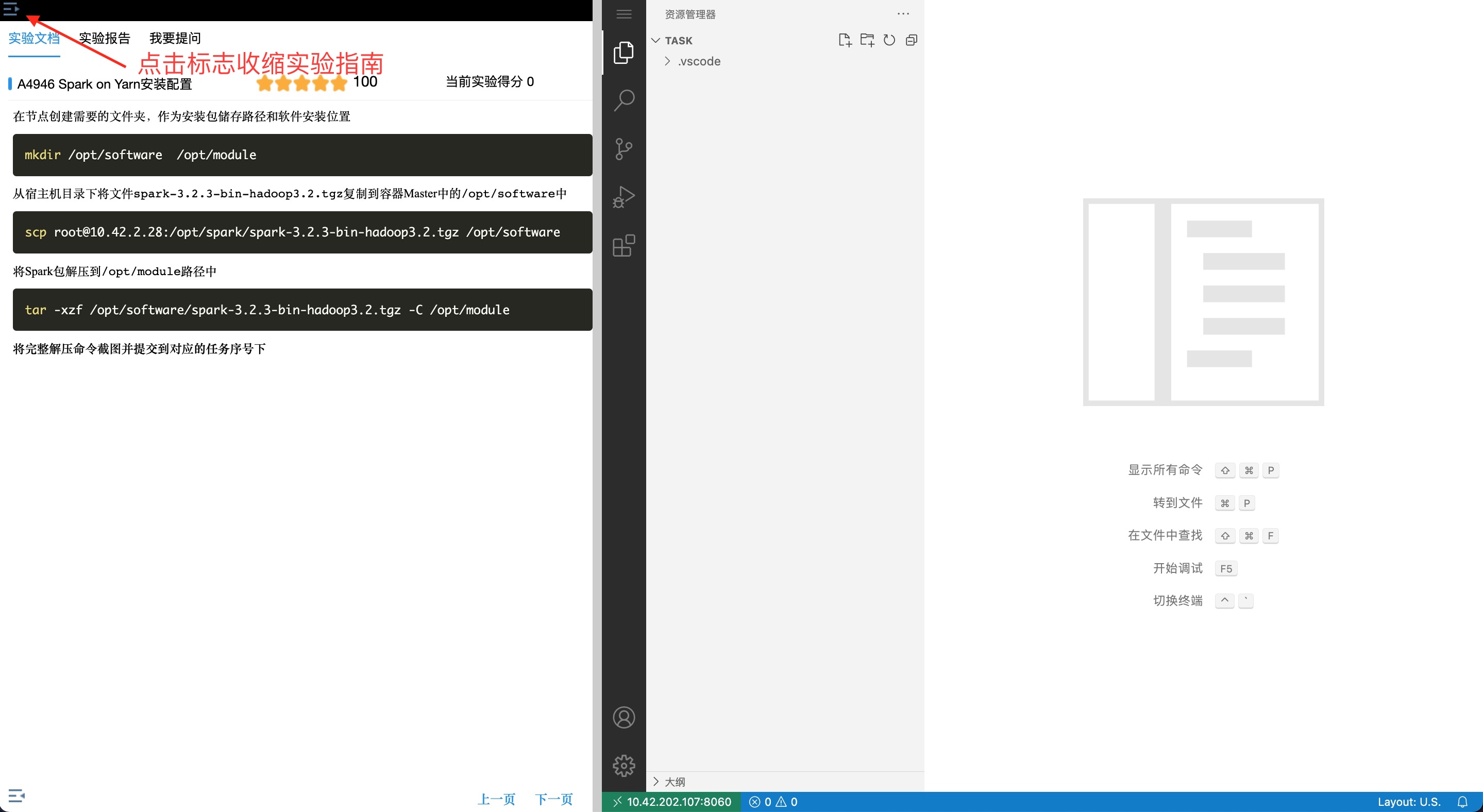 2、 点击环境左上角的“三个横线”的标志,如下图。 最后点击“终端”。
2、 点击环境左上角的“三个横线”的标志,如下图。 最后点击“终端”。 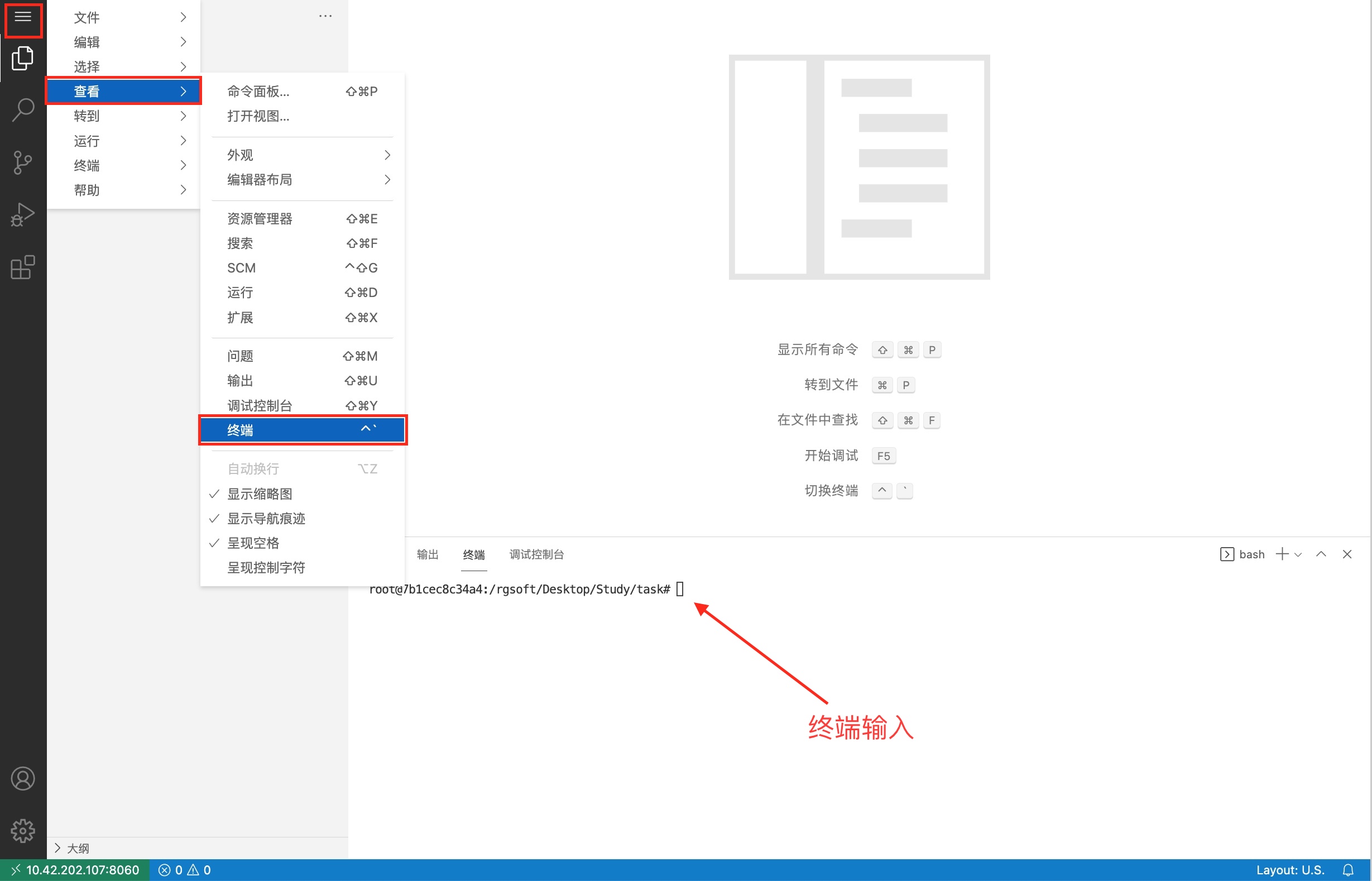 3、 会在右下方看到打开的终端,可直接在终端中进行操作。
3、 会在右下方看到打开的终端,可直接在终端中进行操作。 

—
在节点创建需要的文件夹,作为安装包储存路径和软件安装位置
mkdir /opt/software /opt/module
从宿主机目录下将spark安装包、maven安装包、hudi安装包、jdbc驱动复制到容器Master中的/opt/software路径中。
scp root@10.42.2.28:/opt/maven/apache-maven-3.9.1-bin.tar.gz /opt/software
scp root@10.42.2.28:/opt/hudi/hudi-0.14.0.tar.gz /opt/software
scp root@10.42.2.28:/opt/javalib/mysql-connector-java-5.1.45.jar /opt/software
scp root@10.42.2.28:/opt/spark/spark-3.2.3-bin-hadoop3.2.tgz /opt/software
—
将maven安装包解压到/opt/module路径中:
tar -xzf /opt/software/apache-maven-3.9.1-bin.tar.gz -C /opt/module
cd /opt/module
mv ./apache-maven-3.9.1 ./RepMaven
编辑maven的配置文件settings.xml,配置远程仓库使用阿里云仓库:
cd /opt/module/RepMaven/conf
vim ./settings.xml
找到<mirrors></mirrors>标签,修改标签内的内容为下面: 注意: 下面的地址为平台加速编译用的局域网地址,否则编译过程太久,考试时请替换为阿里云官方地址https://maven.aliyun.com/repository/public。
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://10.42.2.2:8081/repository/maven-public/</url>
</mirror>
修改容器中/etc/profile文件,在文件末添加下面的内容:
# 添加maven的环境变量
export PATH=$PATH:/opt/module/RepMaven/bin
执行下面的命令使添加的spark环境变量生效:
source /etc/profile
在终端运行命令
mvn -v
将命令与结果截图粘并提交到对应的任务序号下
—
将hudi安装包解压到/opt/module路径中:
cd /opt/software/
tar -xzf ./hudi-0.14.0.tar.gz -C /opt/module
cd /opt/module/hudi-release-0.14.0/
将命令与结果截图粘并提交到对应的任务序号下
编辑hudi的项目配置文件pom.xml,配置远程仓库使用阿里云仓库:
vim /opt/module/hudi-release-0.14.0/pom.xml
找到<repositories></repositories>标签,修改标签内的Maven Central内容为下面: 注意: 下面的10.42.2.2:8081地址为平台加速编译用的局域网地址,否则编译过程太久,考试时请替换为阿里云官方地址https://maven.aliyun.com/repository/central。
<repositories>
<repository>
<id>Maven Central</id>
<name>Maven Repository</name>
<url>http://10.42.2.2:8081/repository/maven-public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>cloudera-repo-releases</id>
<url>https://repository.cloudera.com/artifactory/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>confluent</id>
<url>https://packages.confluent.io/maven/</url>
</repository>
</repositories>
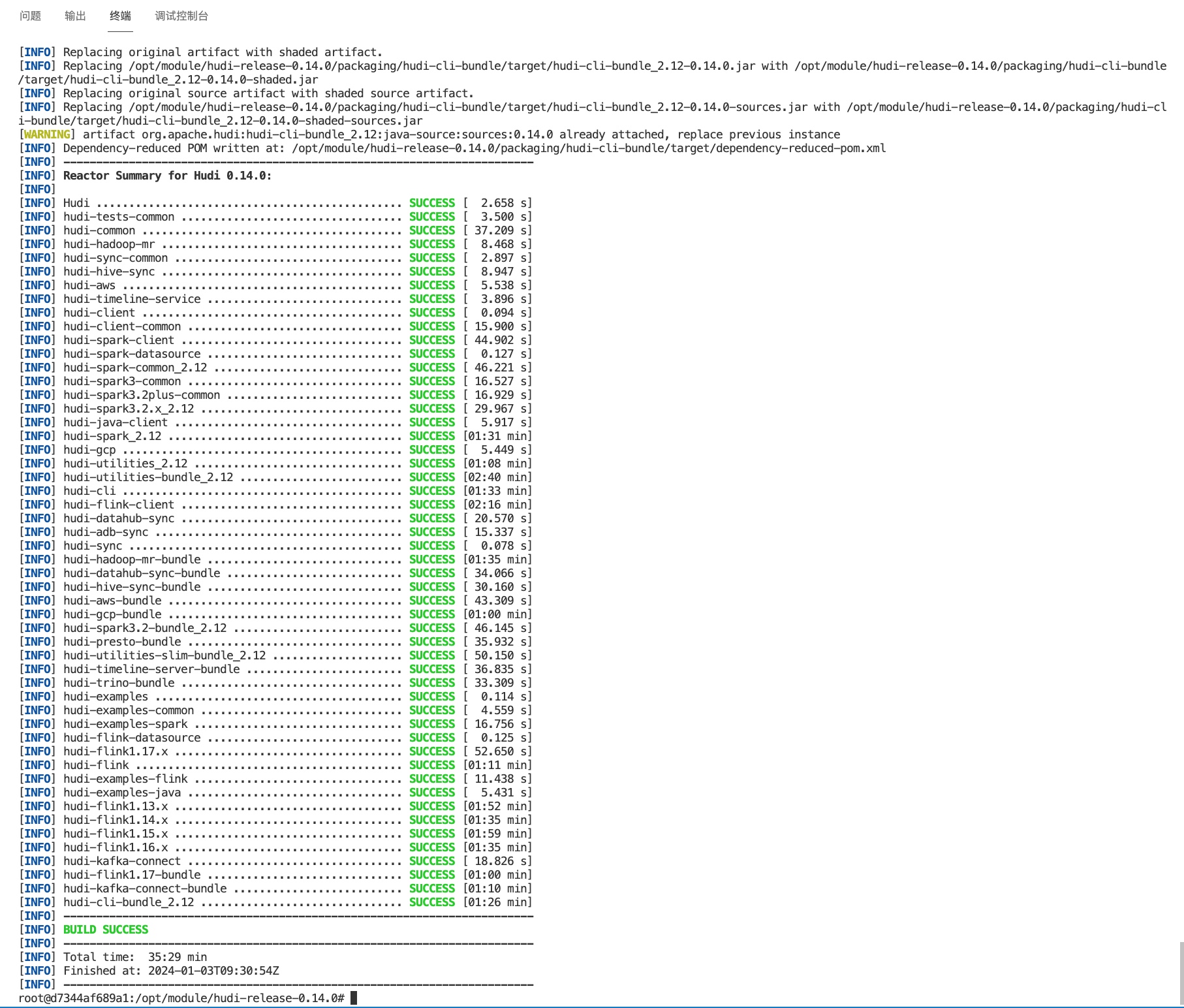
使用maven命令进行构建 注意:虽然我们只用到其中一个hudi-spark-bundle模块的jar包,但如果只构建子模块 hudi-spark-bundle ,可能导致最后的运行案例缺少方法无法运行,所以还是选择全部编译:
-
clean:Maven 构建的一个阶段,用于清理目标目录,删除先前构建生成的文件。 -
package:将项目编译、运行单元测试,并将项目打包成可分发的格式,通常是 JAR 文件或 WAR 文件。 -
DskipTests:这是一个系统属性(System Property),通过 -D 传递给 Maven。在这个命令中,skipTests被设置为true,意味着跳过执行单元测试,可以加快构建过程。
mvn clean package -DskipTests
—
将Spark包解压到/opt/module路径中
tar -xzf /opt/software/spark-3.2.3-bin-hadoop3.2.tgz -C /opt/module
修改容器中/etc/profile文件,在文件末添加下面的内容:
# 添加spark的环境变量
export SPARK_HOME=/opt/module/spark-3.2.3-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
 执行下面的命令使添加的spark环境变量生效:
执行下面的命令使添加的spark环境变量生效:
source /etc/profile
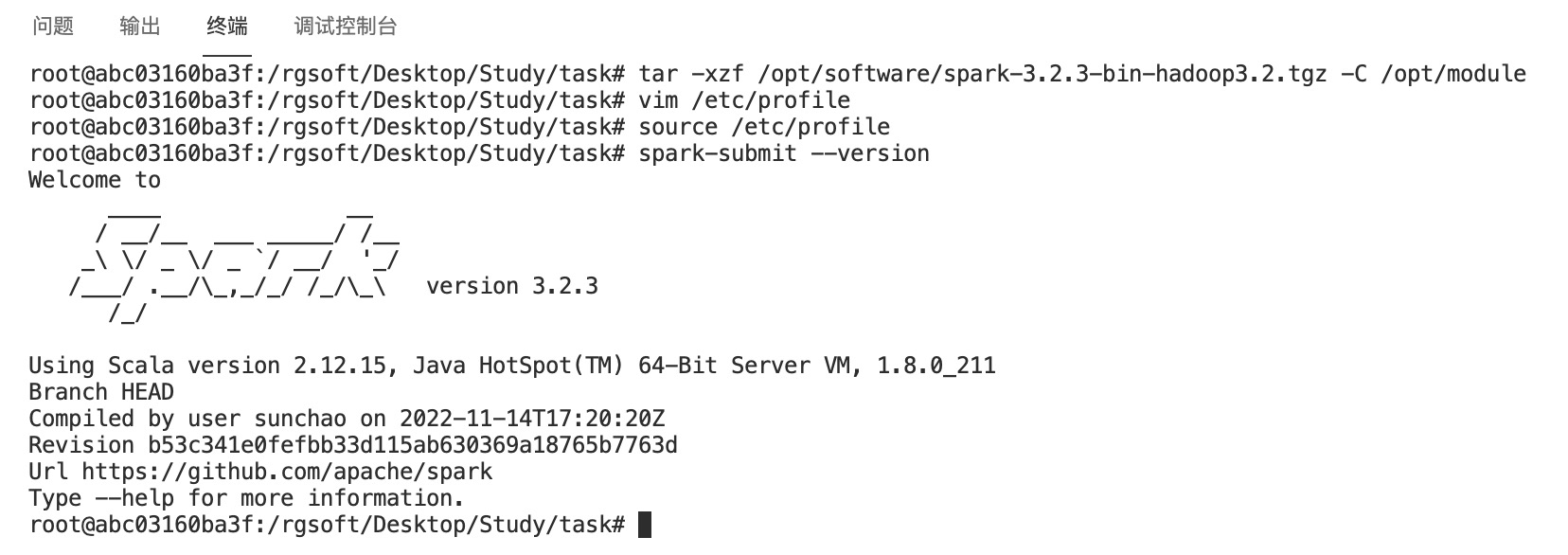
在终端运行命令测试安装成果
spark-submit --version
—
将jdbc驱动、hudi构建的包拷贝到spark的jars子文件夹
cd /opt/module/spark-3.2.3-bin-hadoop3.2
cp -f /opt/software/mysql-connector-java-5.1.45.jar ./jars/
cp -f /opt/module/hudi-release-0.14.0/packaging/hudi-spark-bundle/target/hudi-spark3.2-bundle_2.12-0.14.0.jar ./jars/
创建test.scala文件:
touch ./test.scala
输入试卷内要求的下面的内容:
// 导入了与 Apache Hudi 相关的一些库,包括一些用于读写 Hudi 数据的选项和配置:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
// `tableName` 是 Hudi 表的名称,`basePath` 是 Hudi 表的基础路径,用于存储表的数据和元数据。
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
// 创建一个 `DataGenerator` 实例,然后生成包含 10 条插入语句的数据,将其转换为字符串列表。
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
// 读取数据并写入 Hudi 表:
// 通过 Spark 读取生成的数据,并使用 Hudi 将数据写入指定的表中,其中设置了一些 Hudi 写入选项,如预合并字段、记录键、分区路径等。
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
// 读取 Hudi 表的数据并创建 Spark 临时视图:
// 通过 Spark 读取 Hudi 表的数据,并将其存储在名为 tripsSnapshotDF 的 DataFrame 中。然后,使用 createOrReplaceTempView 方法在 Spark 中创建一个名为 hudi_trips_snapshot 的临时视图。
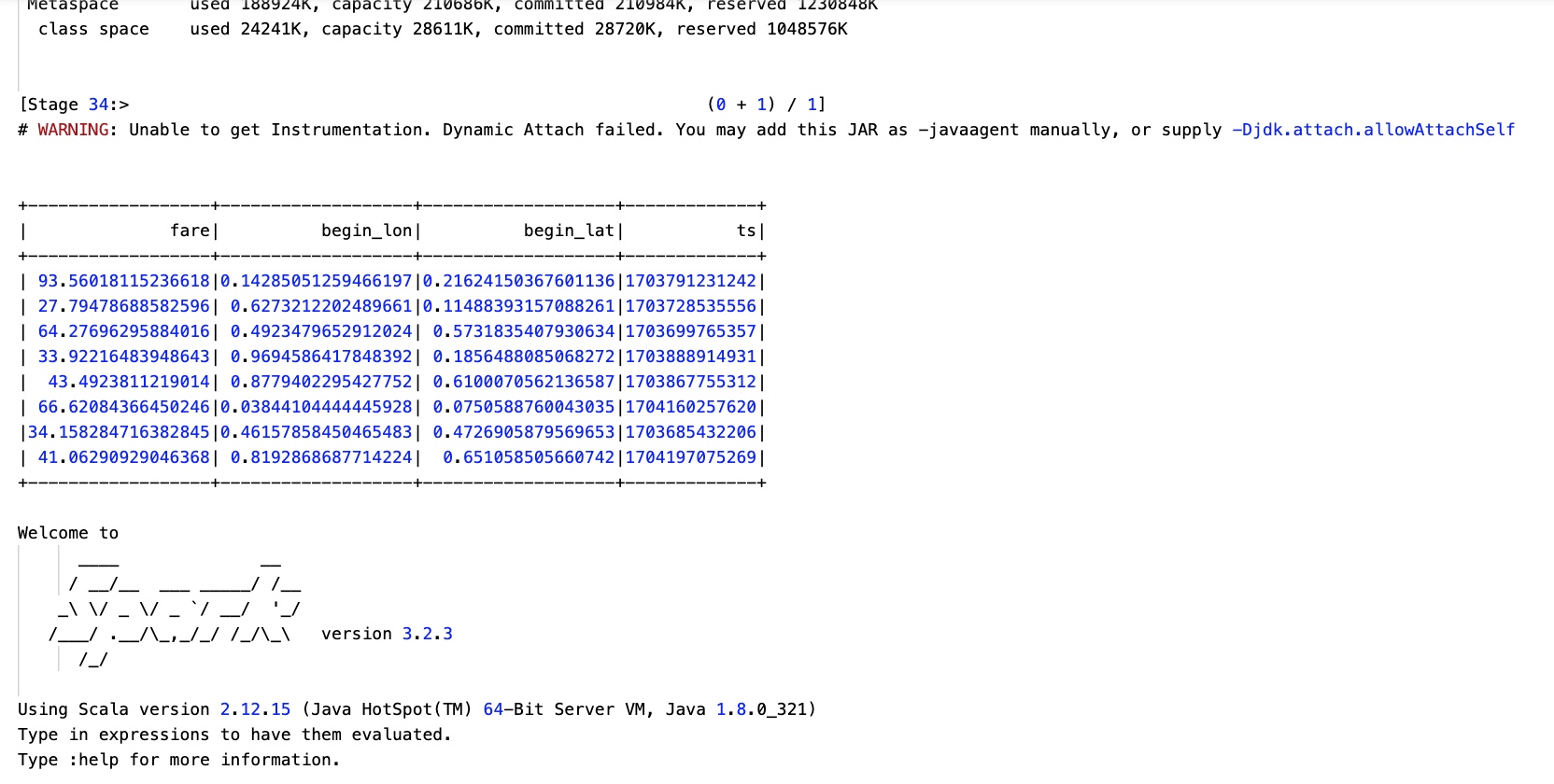
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
// 执行 SQL 查询并显示结果:
// 使用 Spark SQL 执行查询,选择 hudi_trips_snapshot 中 fare 大于 20.0 的记录,并显示结果。
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
最后使用spark-shell来运行:
spark-shell -i ./test.scala
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog'
--conf 'spark.kryo.registrator=org.apache.spark.HoodieSparkKryoRegistrar' > ./hudi-test.log 2>&1
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。











暂无评论内容