

编写Scala代码,使用Flink消费Kafka中Topic为order的数据并进行相应的数据统计计算(订单信息对应表结构order_info,订单详细信息对应表结构order_detail(来源类型和来源编号这两个字段不考虑,所以在实时数据中不会出现),同时计算中使用order_info或order_detail表中create_time或operate_time取两者中值较大者作为EventTime,若operate_time为空值或无此列,则使用create_time填充,允许数据延迟5s,订单状态order_status分别为1001:创建订单、1002:支付订单、1003:取消订单、1004:完成订单、1005:申请退回、1006:退回完成。另外对于数据结果展示时,不要采用例如:1.9786518E7的科学计数法)。
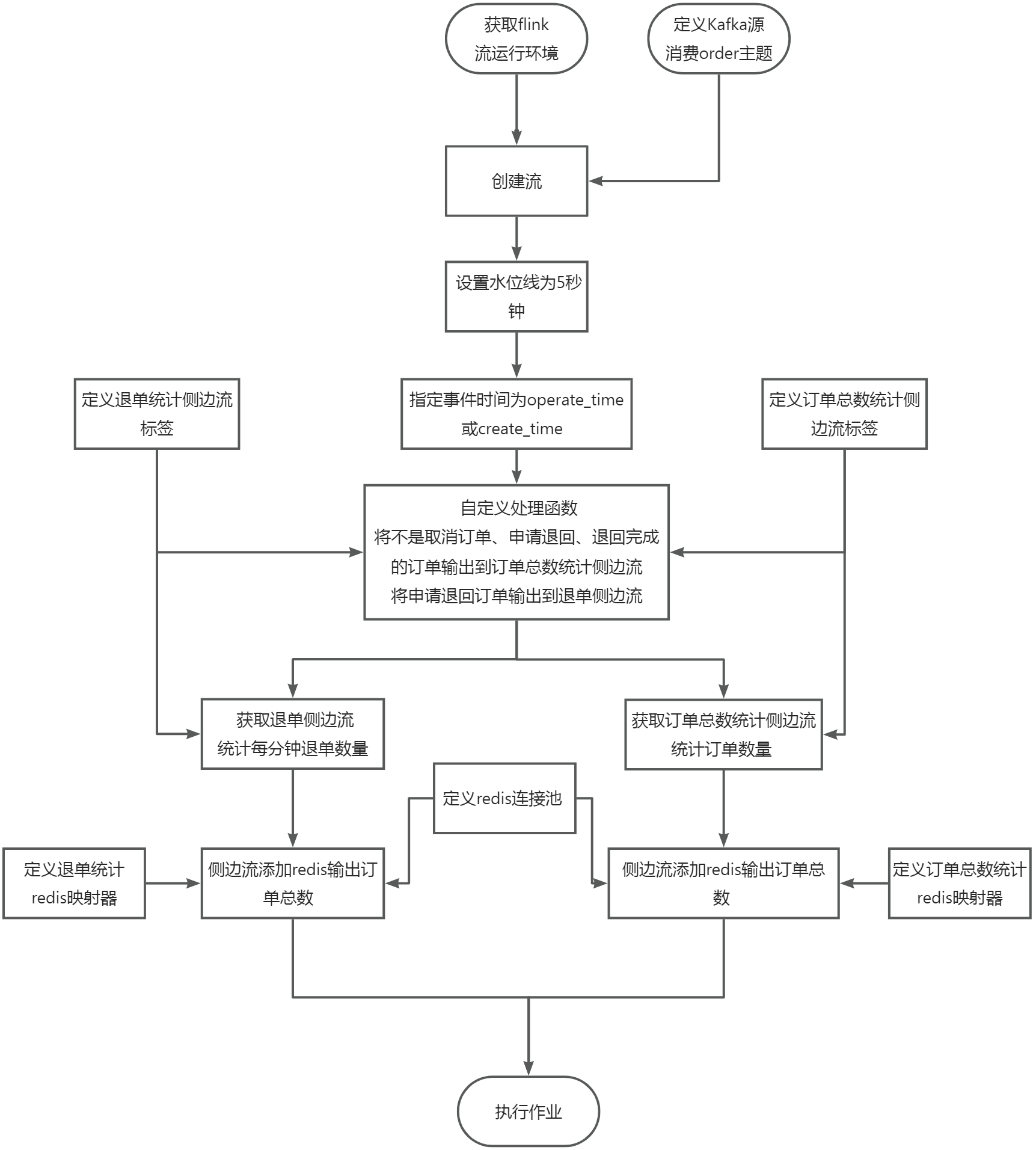
使用Flink消费Kafka中的数据,统计商城实时订单数量(需要考虑订单状态,若有取消订单、申请退回、退回完成则不计入订单数量,其他状态则累加),将key设置成totalcount存入Redis中。使用redis cli以get key方式获取totalcount值,将结果截图粘贴至客户端桌面【Release任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面;
—
—
在flink工程目录的src/main/scala/org/example目录下新建TotalCount.scala文件,新建object对象和main函数,在主方法中获取Flink流运行环境,代码如下:
package org.example
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, TimestampAssigner, TimestampAssignerSupplier, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.table.api.Expressions.$
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.util.Collector
import java.text.SimpleDateFormat
import java.time.Duration
import java.util.Properties
object TotalCount {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
}
}
—
在main函数中定义kafka源,消费kafka的order主题,代码如下:
val source = KafkaSource.builder[String].
setBootstrapServers("localhost:9092").
setTopics("order").
setGroupId("order1").
setStartingOffsets(OffsetsInitializer.earliest()).
setValueOnlyDeserializer(new SimpleStringSchema()).build()
—
在main函数中使用kafka数据源创建flink流,代码如下:
val stream = env.fromSource(source, WatermarkStrategy.noWatermarks[String], "Kafka Source")
—
在main函数中定义订单数量统计侧边流标签,通过标签可以写出侧边流和获取侧边流,代码如下:
val totalcount=OutputTag[(String,String)]("totalcount")
—
根据题目要求,允许数据延迟5s,那么我们就需要设置水位线超时时间为5s,代码如下:
val newstream= stream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness[String](Duration.ofSeconds(5))
—
根据题目要求,计算中使用order_info或order_detail表中create_time或operate_time取两者中值较大者作为EventTime,所以我们需要自定义事件时间为create_time或operate_time较大的时间,代码(使用链式编程接1.6步骤的末尾)如下:
.withTimestampAssigner(
new SerializableTimestampAssigner[String] {
override def extractTimestamp(t: String, l: Long):
Long = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(if (t.split(",")(12) > t.split(",")(11)) t.split(",")(12) else t.split(",")(11)).getTime
}
))
—
根据题目要求,统计商城实时订单数量(需要考虑订单状态,若有取消订单、申请退回、退回完成则不计入订单数量,其他状态则累加),需要在处理函数中将不是取消订单、申请退回、退回完成的订单输出到侧边流,主流中的数据不作处理,调用collector收集即可。码(使用链式编程接1.6步骤的末尾)如下:
.process(new ProcessFunction[String,String]{
override def processElement(i: String, context: ProcessFunction[String, String]#Context, collector: Collector[String]): Unit ={
println("getdataQ"+i)
val orderstatus=i.split(",")(5)
println("orderstatus"+orderstatus)
val orderid=i.split(",")(0)
if(!orderstatus.equals("1003") && !orderstatus.equals("1005") && !orderstatus.equals("1006")){
context.output(totalcount,("totalcount",orderid))
}
collector.collect(i)
}
})
—
获取侧边流,通过map转换根据key统计出订单的数量,代码如下:
val newstream2=newstream.getSideOutput(totalcount).map(t=>("ct",1)).keyBy(t=>t._1).sum(1).map(t=>{
println("redisdata" +String.valueOf(t._2))
String.valueOf(t._2)}
)
—
根据题目要求,统计的结果需要保存到redis中,需要建立redis的连接池,代码如下:
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").build()
—
由于订单的统计结果是在flink中,我们要把结果写入到redis,那么redis就需要知道数据是什么格式,key是什么,value是什么,redis执行的命令是什么,这就需要定义一个映射器来实现,代码如下:
// 实现RedisMapper接口
class MyRedisMapper2 extends RedisMapper[String] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.SET, "totalcount")
override def getKeyFromData(t: String): String = "totalcount"
override def getValueFromData(t: String): String = t
}
—
通过侧边流设置redis的连接池信息和映射器信息就可以将数据保存到redis,代码如下:
newstream2.addSink(new RedisSink[String](conf, new MyRedisMapper2))
—
代码编写好以后,需要调用流运行环境来执行任务,代码如下:
env.execute("Job")
—
在Linux终端执行如下命令,使用maven打包代码
cd /rgsoft/Desktop/Study/task/flink/
/opt/apache-maven-3.9.1/bin/mvn clean
/opt/apache-maven-3.9.1/bin/mvn install
—
在Linux终端执行如下命令,提交jar包到集群
echo "classloader.check-leaked-classloader: false" >> /opt/flink/conf/flink-conf.yaml
export HADOOP_CLASSPATH=`hadoop classpath`
/opt/flink/bin/flink run -t yarn-per-job --detached -c org.example.TotalCount ./target/flink-1.0-SNAPSHOT.jar
—
在redis终端查看写入的结果数据,执行如下命令连接redis,然后查看结果
# 连接redis
redis-cli
# 在redis命令行执行命令
keys *
get totalcount
quit
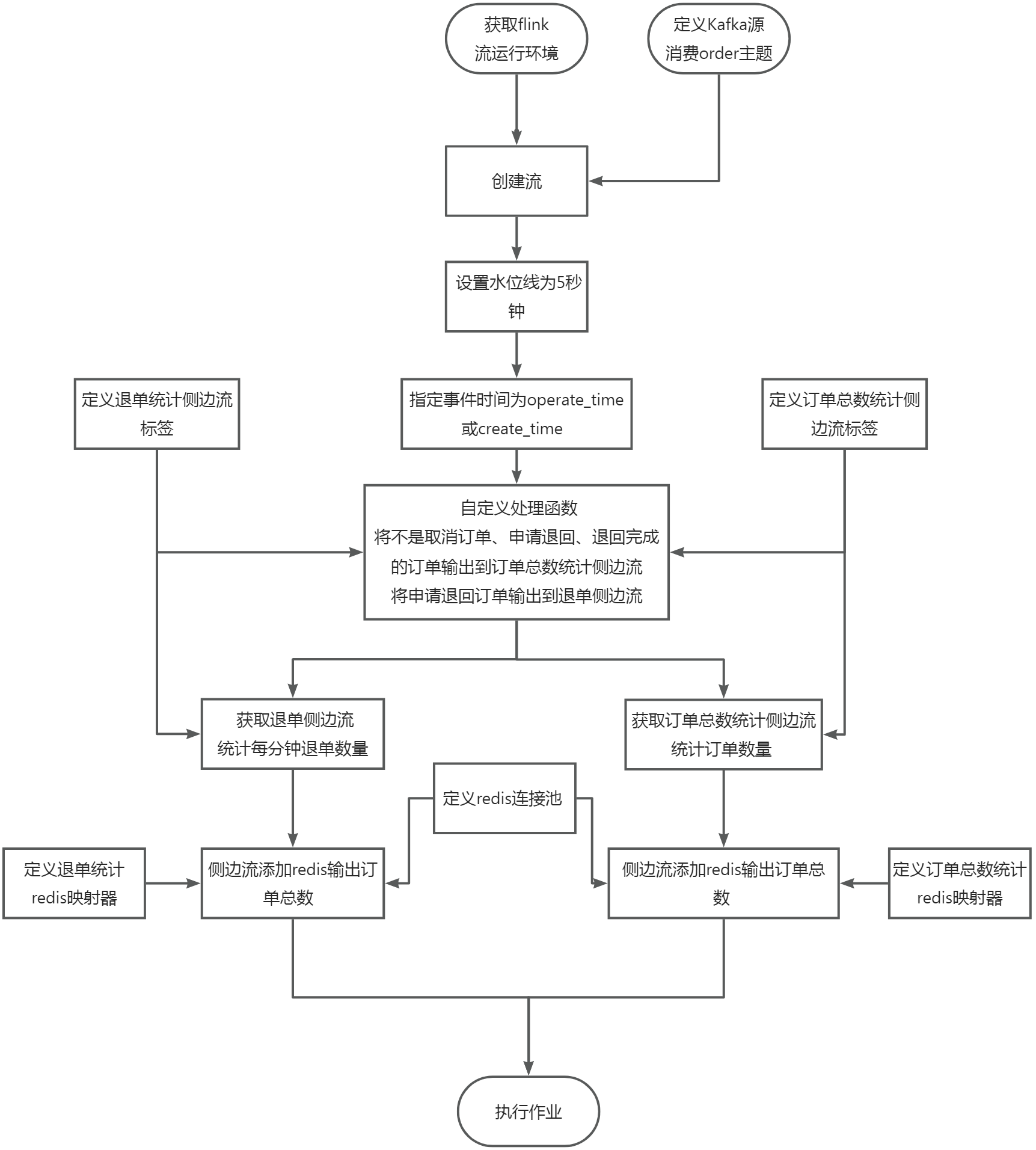
在任务1进行的同时,使用侧边流,统计每分钟申请退回订单的数量,将key设置成refundcountminute存入Redis中。使用redis cli以get key方式获取refundcountminute值,将结果截图粘贴至客户端桌面【Release任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面;
—
—
在flink工程目录的src/main/scala/org/example目录下新建RefundCountMinute.scala文件,新建object对象和main函数,在主方法中获取Flink流运行环境,代码如下:
package org.example
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, TimestampAssigner, TimestampAssignerSupplier, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.{TumblingEventTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.table.api.Expressions.$
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.util.Collector
import java.text.SimpleDateFormat
import java.time.Duration
import java.util.Properties
object RefundCountMinute {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
}
}
—
在main函数中定义kafka源,消费kafka的order主题,代码如下:
val source = KafkaSource.builder[String].
setBootstrapServers("localhost:9092").
setTopics("order").
setGroupId("order2").
setStartingOffsets(OffsetsInitializer.earliest()).
setValueOnlyDeserializer(new SimpleStringSchema()).build()
—
在main函数中使用kafka数据源创建flink流,代码如下:
val stream = env.fromSource(source, WatermarkStrategy.noWatermarks[String], "Kafka Source")
—
在main函数中定义订单数量统计侧边流标签和退单统计侧边流标签,通过标签可以写出侧边流和获取侧边流,代码如下:
val totalcount=OutputTag[(String,String)]("totalcount")
val refundcountminute = OutputTag[(String, String)]("refundcountminute")
—
根据题目要求,允许数据延迟5s,那么我们就需要设置水位线超时时间为5s,代码如下:
val newstream= stream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness[String](Duration.ofSeconds(5))
—
根据题目要求,计算中使用order_info或order_detail表中create_time或operate_time取两者中值较大者作为EventTime,所以我们需要自定义事件时间为create_time或operate_time较大的时间,代码(使用链式编程接1.6步骤的末尾)如下:
.withTimestampAssigner(
new SerializableTimestampAssigner[String] {
override def extractTimestamp(t: String, l: Long):
Long = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(if (t.split(",")(12) > t.split(",")(11)) t.split(",")(12) else t.split(",")(11)).getTime
}
))
—
根据题目要求,统计商城实时订单数量(需要考虑订单状态,若有取消订单、申请退回、退回完成则不计入订单数量,其他状态则累加),需要在处理函数中将不是取消订单、申请退回、退回完成的订单输出到侧边流,另外还需要将申请退单的订单输出到侧边流进行统计,主流中的数据不作处理,调用collector收集即可。码(使用链式编程接2.6步骤的末尾)如下:
.process(new ProcessFunction[String,String]{
override def processElement(i: String, context: ProcessFunction[String, String]#Context, collector: Collector[String]): Unit ={
println("time:"+(if (i.split(",")(12) > i.split(",")(11)) i.split(",")(12) else i.split(",")(11)))
val orderstatus=i.split(",")(5)
println("orderstatus"+orderstatus)
val orderid=i.split(",")(0)
if(!orderstatus.equals("1003") && !orderstatus.equals("1005") && !orderstatus.equals("1006")){
context.output(totalcount,("totalcount",orderid))
}
if (orderstatus.equals("1005")) {
context.output(refundcountminute, ("refundcountminute",orderid))
}
collector.collect(i)
}
})
—
获取侧边流,通过map转换根据key统计出订单的数量,代码如下:
val newstream2=newstream.getSideOutput(totalcount).map(t=>("ct",1)).keyBy(t=>t._1).sum(1).map(t=>{
println("redisdata" +String.valueOf(t._2))
String.valueOf(t._2)}
)
—
获取侧边流,指定窗口时间为1分钟,通过map转换根据key统计出订单的数量,代码如下:
val newstream3=newstream.getSideOutput(refundcountminute).map(t=>("ct",1)).keyBy(t=>t._1).window(TumblingProcessingTimeWindows.of(Time.seconds(60))).sum(1).map(t=>String.valueOf(t._2))
—
根据题目要求,统计的结果需要保存到redis中,需要建立redis的连接池,代码如下:
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").build()
—
由于订单的统计结果是在flink中,我们要把结果写入到redis,那么redis就需要知道数据是什么格式,key是什么,value是什么,redis执行的命令是什么,这就需要定义一个映射器来实现,代码如下:
// 实现RedisMapper接口
class MyRedisMapper2 extends RedisMapper[String] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.SET, "totalcount")
override def getKeyFromData(t: String): String = "totalcount"
override def getValueFromData(t: String): String = t
}
—
由于退单统计的结果是在flink中,我们要把结果写入到redis,那么redis就需要知道数据是什么格式,key是什么,value是什么,redis执行的命令是什么,这就需要定义一个映射器来实现,代码如下:
// 实现RedisMapper接口
class MyRedisMapper3 extends RedisMapper[String] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.SET, "refundcountminute")
override def getKeyFromData(t: String): String = "refundcountminute"
override def getValueFromData(t: String): String = t
}
—
通过侧边流设置redis的连接池信息和映射器信息就可以将数据保存到redis,代码如下:
newstream2.addSink(new RedisSink[String](conf, new MyRedisMapper2))
—
通过侧边流设置redis的连接池信息和映射器信息就可以将数据保存到redis,代码如下:
newstream3.addSink(new RedisSink[String](conf, new MyRedisMapper3))
—
代码编写好以后,需要调用流运行环境来执行任务,代码如下:
env.execute("Job")
—
在Linux终端执行如下命令,使用maven打包代码
cd /rgsoft/Desktop/Study/task/flink/
/opt/apache-maven-3.9.1/bin/mvn clean
/opt/apache-maven-3.9.1/bin/mvn install
—
在Linux终端执行如下命令,提交jar包到集群
export HADOOP_CLASSPATH=`hadoop classpath`
/opt/flink/bin/flink run -t yarn-per-job --detached -c org.example.RefundCountMinute ./target/flink-1.0-SNAPSHOT.jar
—
在redis终端查看写入的结果数据,执行如下命令连接redis,然后查看结果
# 连接redis
redis-cli
# 在redis命令行执行命令
keys *
get refunccountminute
quit
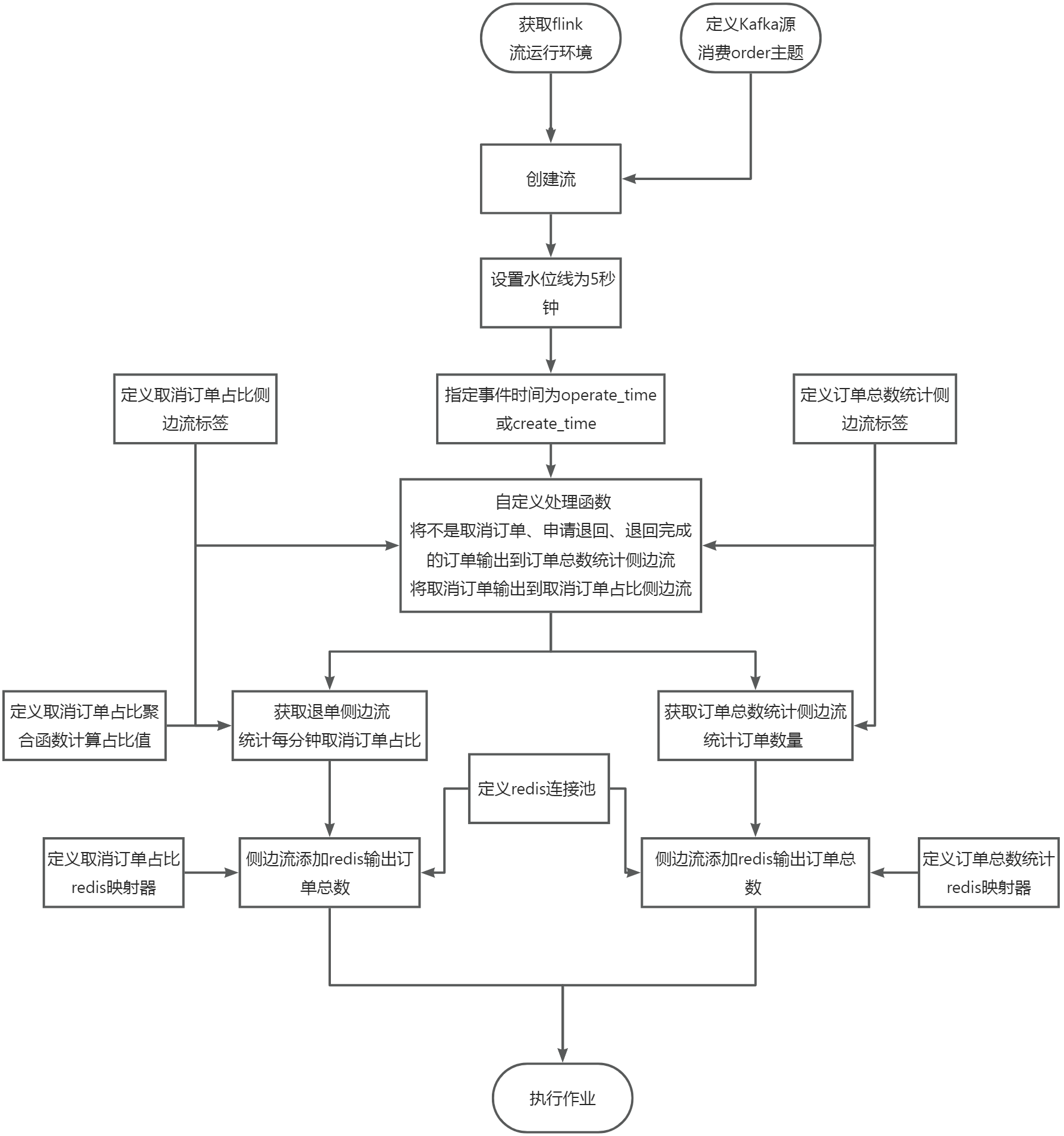
在任务1进行的同时,使用侧边流,计算每分钟内状态为取消订单占所有订单的占比,将key设置成cancelrate存入Redis中,value存放取消订单的占比(为百分比,保留百分比后的一位小数,四舍五入,例如12.1%)。使用redis cli以get key方式获取cancelrate值,将结果截图粘贴至客户端桌面【Release任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面。1分钟以上,第一次截图放前面,第二次截图放后面。
—
—
在flink工程目录的src/main/scala/org/example目录下新建CancelRate.scala文件,新建object对象和main函数,在主方法中获取Flink流运行环境,代码如下:
package org.example
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, TimestampAssigner, TimestampAssignerSupplier, Watermark, WatermarkGenerator, WatermarkGeneratorSupplier, WatermarkOutput, WatermarkStrategy}
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.connector.kafka.source.KafkaSource
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.assigners.{TumblingEventTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
import org.apache.flink.streaming.util.serialization.SimpleStringSchema
import org.apache.flink.table.api.Expressions.$
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.util.Collector
import java.text.SimpleDateFormat
import java.time.Duration
import java.util.Properties
object CancelRate {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
}
}
—
在main函数中定义kafka源,消费kafka的order主题,代码如下:
val source = KafkaSource.builder[String].
setBootstrapServers("localhost:9092").
setTopics("order").
setGroupId("order3").
setStartingOffsets(OffsetsInitializer.earliest()).
setValueOnlyDeserializer(new SimpleStringSchema()).build()
—
在main函数中使用kafka数据源创建flink流,代码如下:
val stream = env.fromSource(source, WatermarkStrategy.noWatermarks[String], "Kafka Source")
—
在main函数中定义订单数量统计侧边流标签和取消订单占比侧边流标签,通过标签可以写出侧边流和获取侧边流,代码如下:
//使用侧边流
val totalcount = OutputTag[(String, String)]("totalcount")
val cancelrate = OutputTag[(String, Int, Int)]("cancelrate")
—
根据题目要求,允许数据延迟5s,那么我们就需要设置水位线超时时间为5s,代码如下:
val newstream= stream.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness[String](Duration.ofSeconds(5))
—
根据题目要求,计算中使用order_info或order_detail表中create_time或operate_time取两者中值较大者作为EventTime,所以我们需要自定义事件时间为create_time或operate_time较大的时间,代码(使用链式编程接1.6步骤的末尾)如下:
.withTimestampAssigner(
new SerializableTimestampAssigner[String] {
override def extractTimestamp(t: String, l: Long):
Long = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(if (t.split(",")(12) > t.split(",")(11)) t.split(",")(12) else t.split(",")(11)).getTime
}
))
—
根据题目要求,统计商城实时订单数量(需要考虑订单状态,若有取消订单、申请退回、退回完成则不计入订单数量,其他状态则累加),需要在处理函数中将不是取消订单、申请退回、退回完成的订单输出到侧边流,另外还需要将取消订单输和全部订单出到侧边流计算取消订单占比,主流中的数据不作处理,调用collector收集即可。码(使用链式编程接3.6步骤的末尾)如下:
.process(new ProcessFunction[String,String]{
override def processElement(i: String, context: ProcessFunction[String, String]#Context, collector: Collector[String]): Unit ={
val orderstatus=i.split(",")(5)
println("orderstatus"+orderstatus)
val orderid=i.split(",")(0)
if(!orderstatus.equals("1003") && !orderstatus.equals("1005") && !orderstatus.equals("1006")){
context.output(totalcount,("totalcount",orderid))
}
if (orderstatus.equals("1003") ) {
context.output(cancelrate, ("order", 1, 1))
}else{
context.output(cancelrate, ("order", 0, 1))
}
collector.collect(i)
}
})
—
获取侧边流,通过map转换根据key统计出订单的数量,代码如下:
val newstream2=newstream.getSideOutput(totalcount).map(t=>("ct",1)).keyBy(t=>t._1).sum(1).map(t=>{
println("redisdata" +String.valueOf(t._2))
String.valueOf(t._2)}
)
—
根据题目要求需要计算取消订单的占比,我们可以通过自定义一个聚合函数同时统计出订单总量和取消订单的数量,然后计算出取消订单的占比值,代码如下:
// 实现自定义聚合函数
class CancelRate extends AggregateFunction[(String, Int, Int), (Long, Long), Double] {
override def createAccumulator(): (Long, Long) = (0L, 0L)
// 每来一条数据,都会进行add叠加聚合
override def add(in: (String, Int, Int), acc: (Long, Long)): (Long, Long) = (acc._1 + in._2, acc._2 + in._3)
// 返回最终计算结果
override def getResult(acc: (Long, Long)): Double = acc._1.toDouble / acc._2.toDouble
override def merge(acc: (Long, Long), acc1: (Long, Long)): (Long, Long) = ???
}
—
获取侧边流,指定窗口时间为1分钟,通过调用自定义聚合函数实现取消订单占比计算,代码如下:
val newstream4= newstream.getSideOutput(cancelrate).keyBy(t=>t._1).window(TumblingProcessingTimeWindows.of(Time.seconds(60)))
.aggregate(new CancelRate).map(t=> {
println("rate:"+t)
String.format("%.1f", Double.box(t * 100)) + "%"
}
)
—
根据题目要求,统计的结果需要保存到redis中,需要建立redis的连接池,代码如下:
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").build()
—
由于订单的统计结果是在flink中,我们要把结果写入到redis,那么redis就需要知道数据是什么格式,key是什么,value是什么,redis执行的命令是什么,这就需要定义一个映射器来实现,代码如下:
// 实现RedisMapper接口
class MyRedisMapper2 extends RedisMapper[String] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.SET, "totalcount")
override def getKeyFromData(t: String): String = "totalcount"
override def getValueFromData(t: String): String = t
}
—
由于退单统计的结果是在flink中,我们要把结果写入到redis,那么redis就需要知道数据是什么格式,key是什么,value是什么,redis执行的命令是什么,这就需要定义一个映射器来实现,代码如下:
// 实现RedisMapper接口
class MyRedisMapper4 extends RedisMapper[String] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.SET, "cancelrate")
override def getKeyFromData(t: String): String = "cancelrate"
override def getValueFromData(t: String): String = t
}
—
通过侧边流设置redis的连接池信息和映射器信息就可以将数据保存到redis,代码如下:
newstream2.addSink(new RedisSink[String](conf, new MyRedisMapper2))
—
通过侧边流设置redis的连接池信息和映射器信息就可以将数据保存到redis,代码如下:
newstream4.addSink(new RedisSink[String](conf, new MyRedisMapper4))
—
代码编写好以后,需要调用流运行环境来执行任务,代码如下:
env.execute("Job")
—
在Linux终端执行如下命令,使用maven打包代码
cd /rgsoft/Desktop/Study/task/flink/
/opt/apache-maven-3.9.1/bin/mvn clean
/opt/apache-maven-3.9.1/bin/mvn install
—
在Linux终端执行如下命令,提交jar包到集群
export HADOOP_CLASSPATH=`hadoop classpath`
/opt/flink/bin/flink run -t yarn-per-job --detached -c org.example.CancelRate ./target/flink-1.0-SNAPSHOT.jar
—
在redis终端查看写入的结果数据,执行如下命令连接redis,然后查看结果
# 连接redis
redis-cli
# 在redis命令行执行命令
keys *
get cancelrate
quit
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。








暂无评论内容