

大数据 第6页
排序
Spark合并Hive ODS离线数据和HBase实时数据,并存入Hive DWD层
任务描述抽取 ods 库中表 table4 最新分区的数据,并结合 HBase 中 table4 offline表中的数据合并抽取到 dwd 库中 fact table4 的分区表,分区字段为etl date 且值与 ods 库的相对应表该值相等...

4.8 Scala集合:Option
在Scala中,Option[T]是给定类型的0或1个元素的容器。Option 是一个数据类型,用来表明一些数据的“有”或“无”,可以是Some[T]或None[T],其中T可以是任何给定类型。一个Some 实例可以存储任...
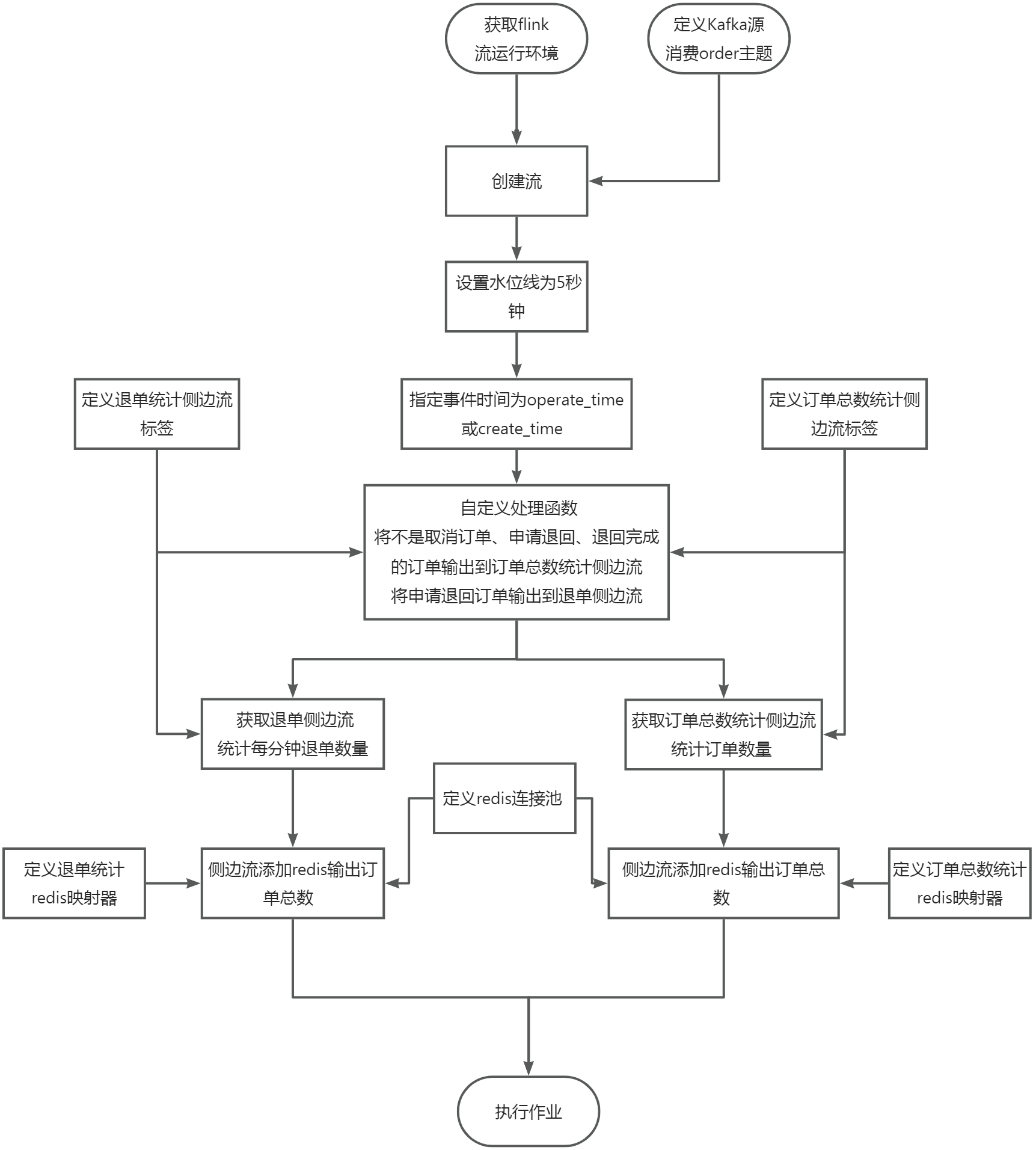
4-3.大数据国赛第2套任务D-子任务二:Flink处理Kafka中的数据
任务要求1 :1.1实现思路1.2获取Flink流运行环境1.3定义Kafka源1.4创建流1.5定义订单数量统计侧边流标签1.6设置水位线1.7设置事件时间1.8自定义处理函数1.9统计订单数量1.10创建redis连接池1.11...

前端框架vue.js系列教程(7)-vue.js使用Fetch API访问RESTful API接口示例
前端框架vue.js系列教程:安装配置node.js和npmvue.js工程项目创建vue.js框架应用开发vue.js单页面应用开发vue.js中实现echarts绘图vue.js远程访问RESTful API接口示例vue.js使用Fetch API访问R...
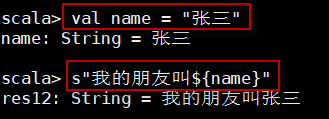
8.2 字符串插值
Scala中的String构建在Java中的String之上,并添加了额外的特性,如字符串插值(字符串插值是一种将字符串内的值与变量相结合的机制)。字符串插值是根据数据创建字符串的过程。用户可以将任...
2.4 数组
Scala语言中提供的数组是用来存储固定大小的同类型元素的。数组的第一个元素索引为0,最后一个元素的索引为元素总数减1。Scala中数组分为定长数组和变长数组。创建定长数组Array的两种方式:先...
2024年重庆甘肃安徽等省职业院校技能大赛_大数据应用开发样题解析-模块B:数据采集-任务一:离线数据采集
任务描述编写Scala 工程代码, 将MySQL 的ds_db01 库中表order_master、order_detail、coupon_info、coupon_use、product_browse、product_info、customer_inf 、customer_login_log 、order_ca...
5.8 尾递归函数
在本节中,我们将学习如何创建尾递归(tail recursive)函数,以及如何使用@annotation.tailrec注解,这将指示编译器应用任何进一步的优化。如何定义尾递归函数?在下面的示例中,我们定义一个...

1-5.Hive安装配置
实验环境实验准备实验内容一、初始化hadoop集群二、安装配置MySQL 5.7元数据库三、下载所需安装包四、安装配置Hive运行环境 实验环境Ubuntu 18.04Oracle JDK 1.8Hadoop 3.2.4Hive 3.1.3实验...

4.1 安装Apache Flume
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受...

1.1 Scala简介
Scala是一种非常适合开发大数据应用程序的语言,是使用Apache Spark的首选语言。使用Scala语言来学习Spark,具有以下优点:首先,开发人员可以通过使用Scala实现显著的生产力提升。其次,它帮助...
4.7 Scala集合:Range和Tuple
RangeRange定义一个范围,指定开始、结束和步长,通常用于填充数据结构和遍历for循环。object RangeDemo { def main(args: Array[String]): Unit = { // 使用方法to来创建Range(包含上限) ...
5-1.大数据国赛数据可视化-用柱状图展示各省份消费额的中位数
实验环境实验准备实验内容一、下载安装vue cli二、创建vue.js项目三、编辑App.vue添加MyCharts组件四、写出MyCharts数据可视化组件模板代码五、在模板里添加处理数据的逻辑代码 实验环境Ubun...
8.1 字符串基本使用和相等性判断
在 Scala 中,String 是一个不可变的对象,所以该对象不可被修改。这就意味着如果修改字符串就会产生一个新的字符串对象。但其他对象,如数组就是可变的对象。字符串基本使用Scala中字符串的数...
2.3 运算符
数据存储在变量中,要对数据进行运算,就需要使用运算符。Scala语言中提供了这几种运算符:算术运算符、关系运算符、逻辑运算符、位运算符、赋值运算符等。注:实际上,Scala没有传统意义上的运...
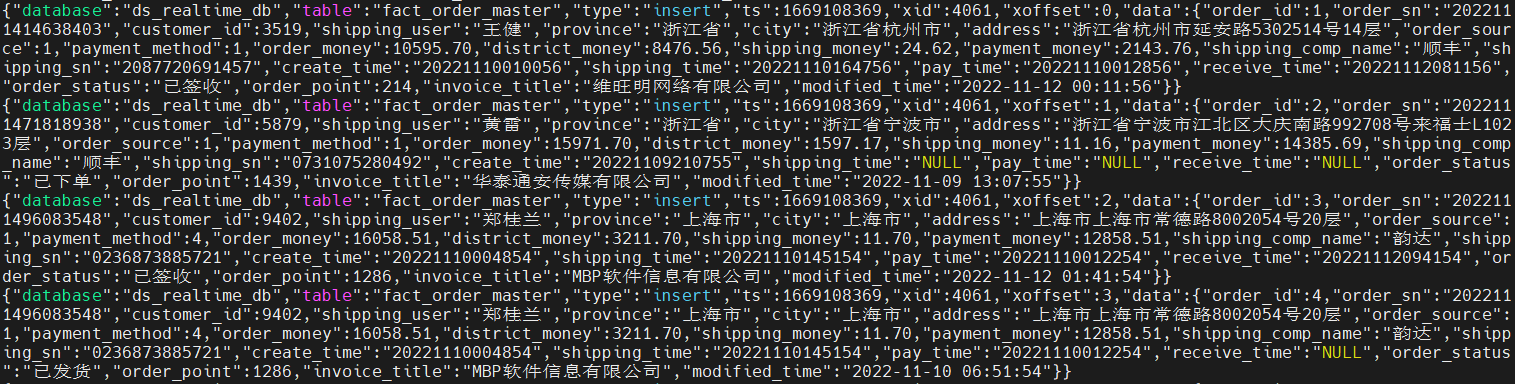
2024年重庆甘肃安徽等省职业院校技能大赛_大数据应用开发样题解析-模块B:数据采集-任务二:实时数据采集
本任务共有两个子任务组成:实时数据采集子任务1实时数据采集子任务2子任务1子任务1描述1、在主节点使用Flume 采集实时数据生成器25001 端口的socket 数据(实时数据生成器脚本为主节点/data_lo...
