


-
Ubuntu 18.04
-
实验环境SSH的root账号密码默认为root
-
Oracle JDK 1.8
-
Hadoop 3.2.4
-
点击
开始实验按钮,打开当前实验所有镜像环境
-
进入实验环境后, 点击左上角收缩实验指南
-
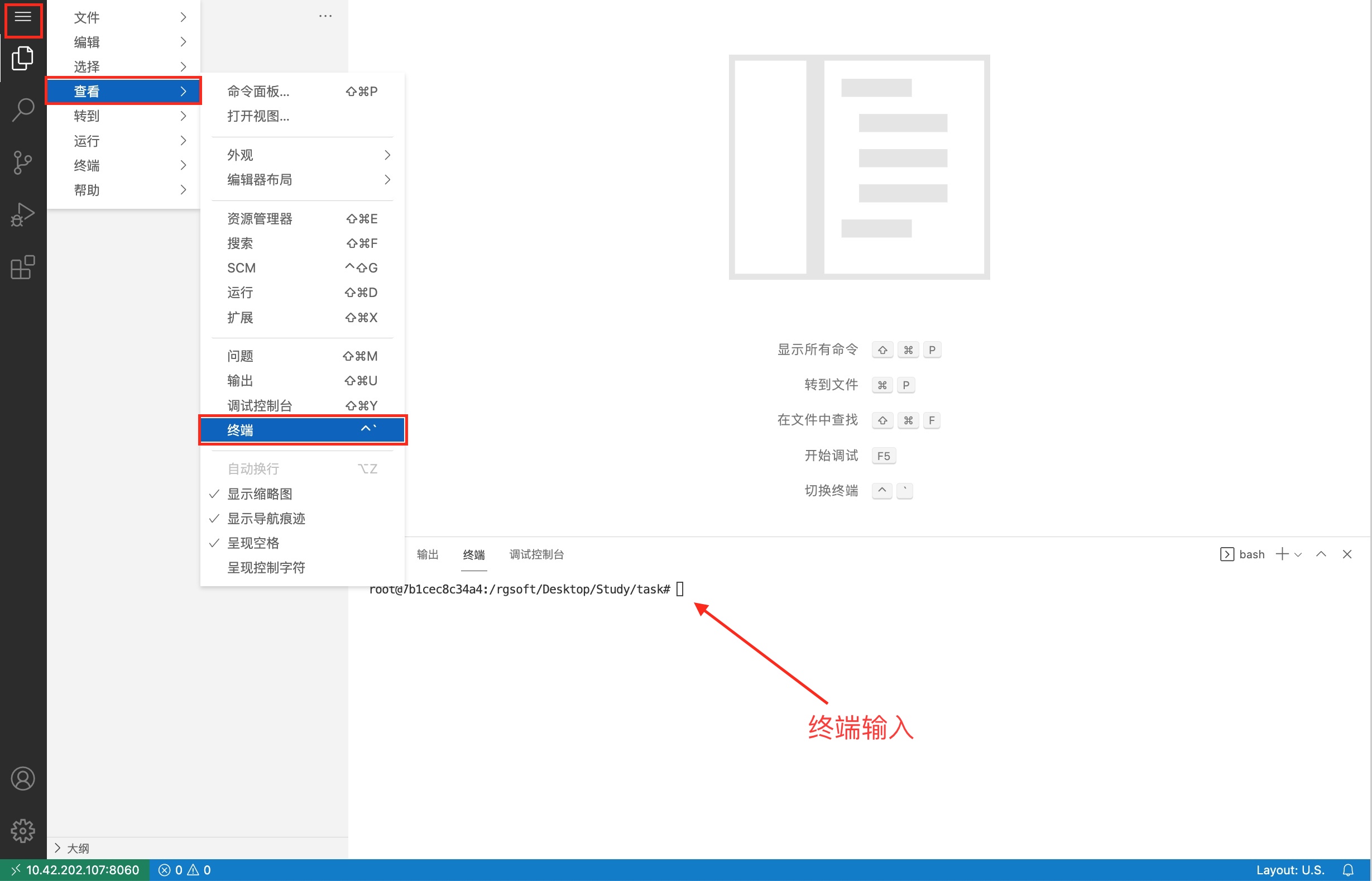
点击环境左上角的“三个横线”的标志,如下图。 最后点击“终端”。
-
会在右下方看到打开的终端,可直接在终端中进行操作。


在节点创建需要的文件夹,作为安装包储存路径和软件安装位置
mkdir /opt/software /opt/module
从宿主机目录下将文件hadoop-3.1.3.tar.gz、jdk-8u211-linux-x64.tar.gz 复制到容器Master中的/opt/software路径中,ssh密码为root。
scp root@10.42.2.28:/opt/jdk/jdk-8u211-linux-x64.tar.gz /opt/software
scp root@10.42.2.28:/opt/hadoop/hadoop-3.2.4.tar.gz /opt/software
将Master节点JDK安装包解压到/opt/module路径中:
tar -xzf /opt/software/jdk-8u211-linux-x64.tar.gz -C /opt/module
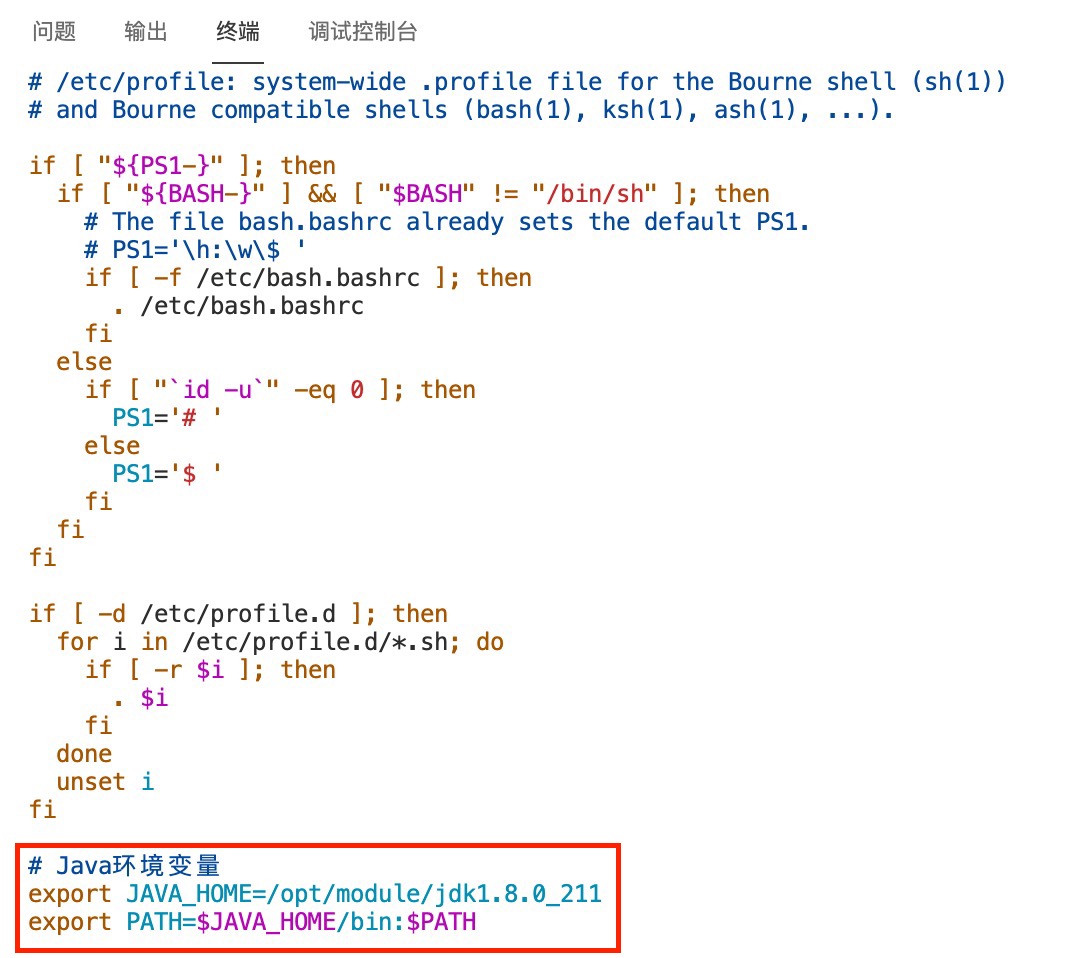
将JDK解压命令截图并提交到对应的任务序号下 修改容器中/etc/profile文件,在文件末添加下面的内容:
# Java环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_211
export PATH=$JAVA_HOME/bin:$PATH
 执行下面的命令使添加的JDK环境变量生效:
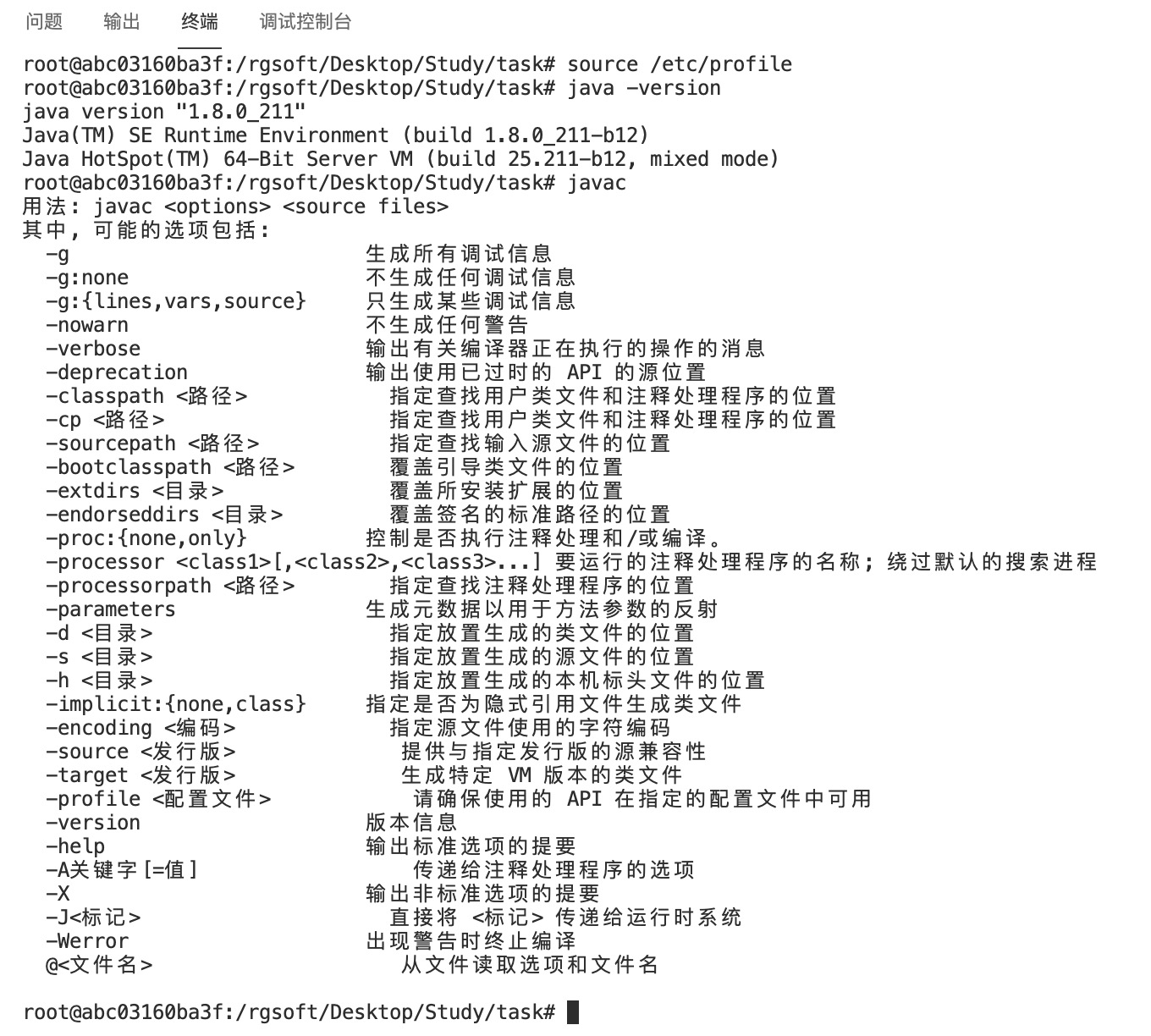
执行下面的命令使添加的JDK环境变量生效:
source /etc/profile
配置完毕后在Master节点终端分别执行java -version和javac命令:
java -version
javac
 将命令行执行结果分别截图并提交到对应的任务序号下
将命令行执行结果分别截图并提交到对应的任务序号下
在master节点创建需要的文件夹
mkdir -p /root/tmpdata /root/dfsdata/{namenode,datanode}
在Master将Hadoop解压到/opt/module
tar -xzf /opt/software/hadoop-3.2.4.tar.gz -C /opt/module/
修改节点环境中的/etc/profile文件,在文件末添加下面的内容:
# 添加Hadoop的环境变量
export HADOOP_HOME=/opt/module/hadoop-3.2.4
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
 执行下面的命令使添加的Hadoop环境变量生效:
执行下面的命令使添加的Hadoop环境变量生效:
source /etc/profile
配置/opt/module/hadoop-3.2.4/etc/hadoop路径下的6个重要的配置文件: core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,hadoop-env.sh,workers 下面是添加好的文件的内容:
-
core-site.xml 使用vim命令编辑文件内容:
cd /opt/module/hadoop-3.2.4/etc/hadoop
vim ./core-site.xml
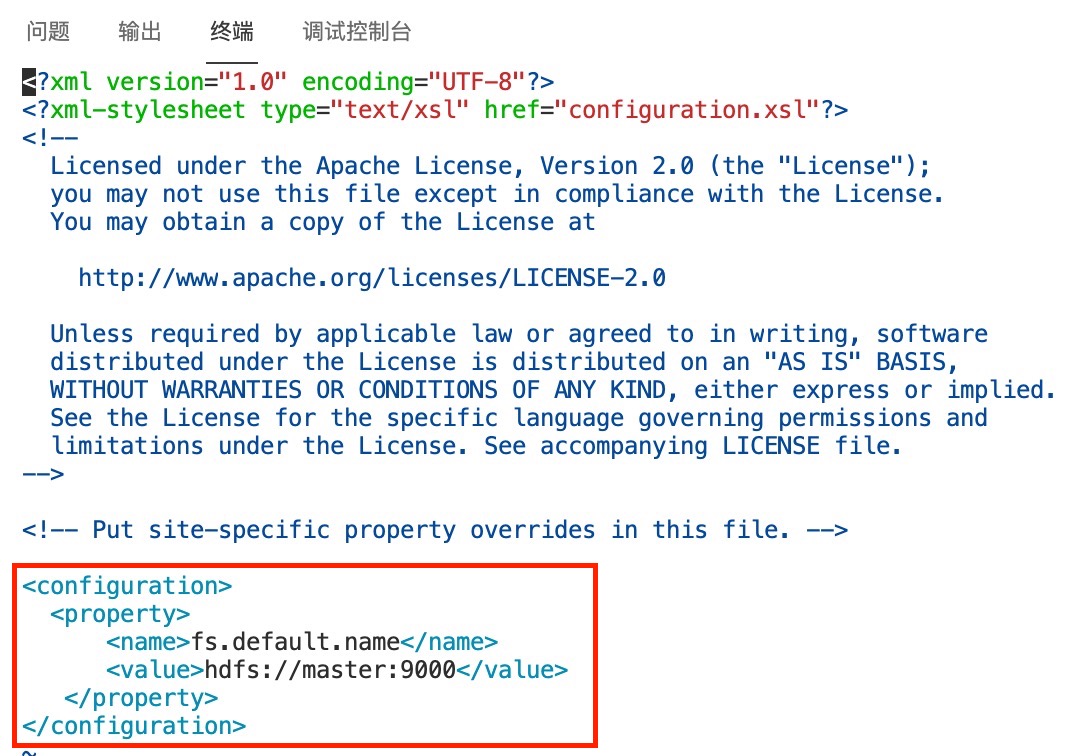
编辑好的内容如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
 \2. hdfs-site.xml 接下来编辑文件:
\2. hdfs-site.xml 接下来编辑文件:
vim ./hdfs-site.xml
编辑好的内容如下:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/dfsdata/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
 \3. yarn-site.xml 接下来编辑文件:
\3. yarn-site.xml 接下来编辑文件:
vim ./yarn-site.xml
编辑好的内容如下:
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
 \4. mapred-site.xml 接下来编辑文件:
\4. mapred-site.xml 接下来编辑文件:
vim ./mapred-site.xml
编辑好的内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
 \5. hadoop-env.sh 接下来编辑文件:
\5. hadoop-env.sh 接下来编辑文件:
vim ./hadoop-env.sh
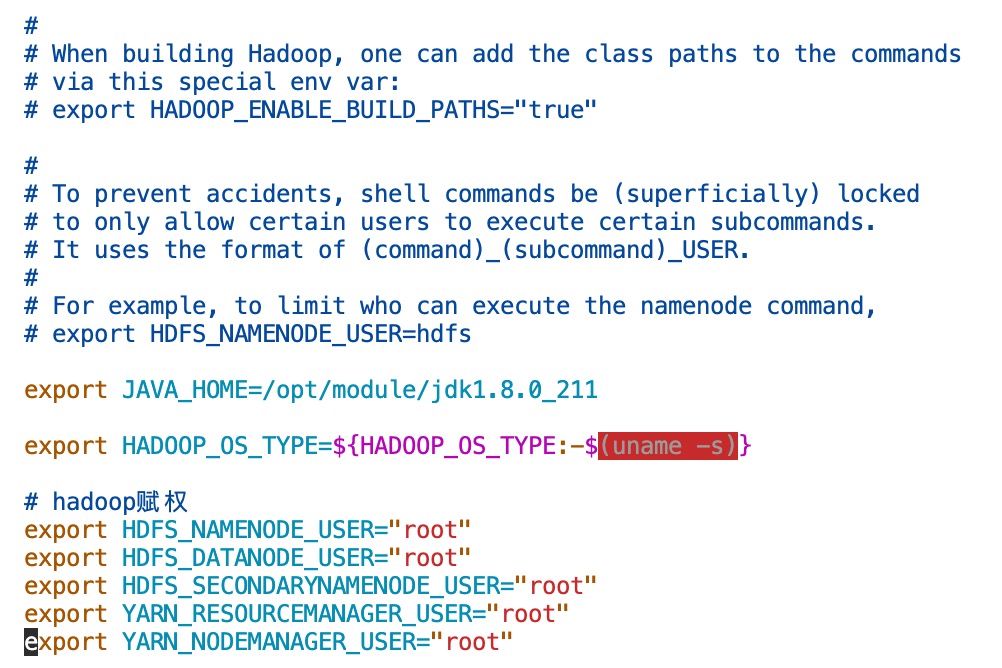
添加的内容如下:
export JAVA_HOME=/opt/module/jdk1.8.0_211
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
# hadoop赋权
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
 \6. workers 接下来编辑文件:
\6. workers 接下来编辑文件:
vim ./workers
编辑好的内容如下:
slave1
slave2

这样,Hadoop分布式安装所需要的配置文件都编辑好了。
使用命令查看自己所有节点环境的IP信息:
ip addr show
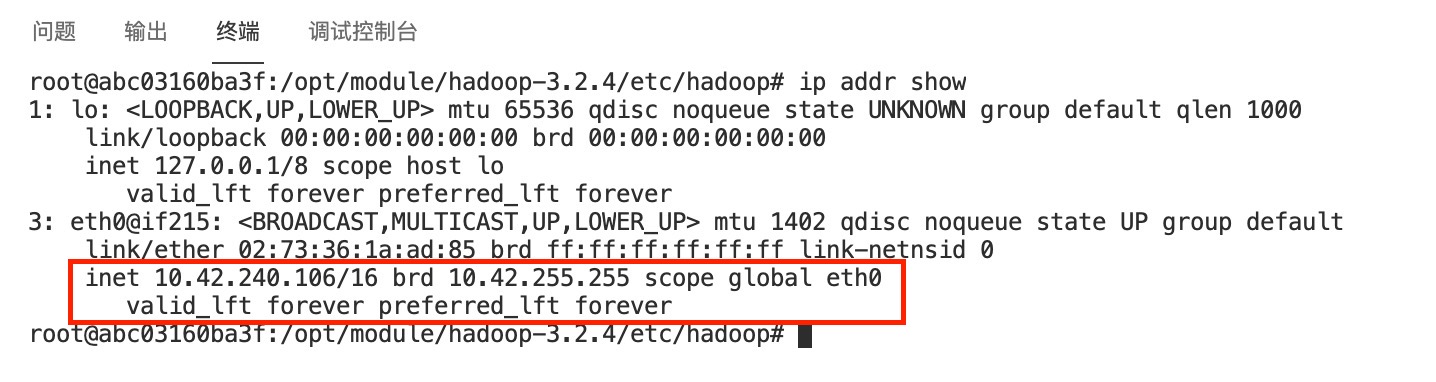 把所有节点的IP记录下来,将三个节点分别命名为master、slave1、slave2,取1个IP作为master节点,其余做slave节点。 修改容器中
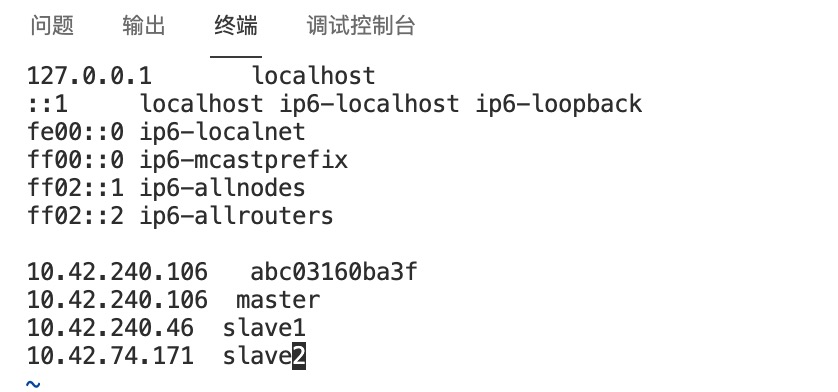
把所有节点的IP记录下来,将三个节点分别命名为master、slave1、slave2,取1个IP作为master节点,其余做slave节点。 修改容器中/etc/hosts文件,根据自己的节点的IP信息,在文件末添加类似下面的内容:
10.42.240.106 master
10.42.240.46 slave1
10.42.74.171 slave2
在master节点使用命令生成key,需要填入的内容直接留空即可
ssh-keygen -b 4096
 使用下面的命令把master节点的公钥拷贝到包括master节点的所有的节点,默认密码为
使用下面的命令把master节点的公钥拷贝到包括master节点的所有的节点,默认密码为root
ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave2
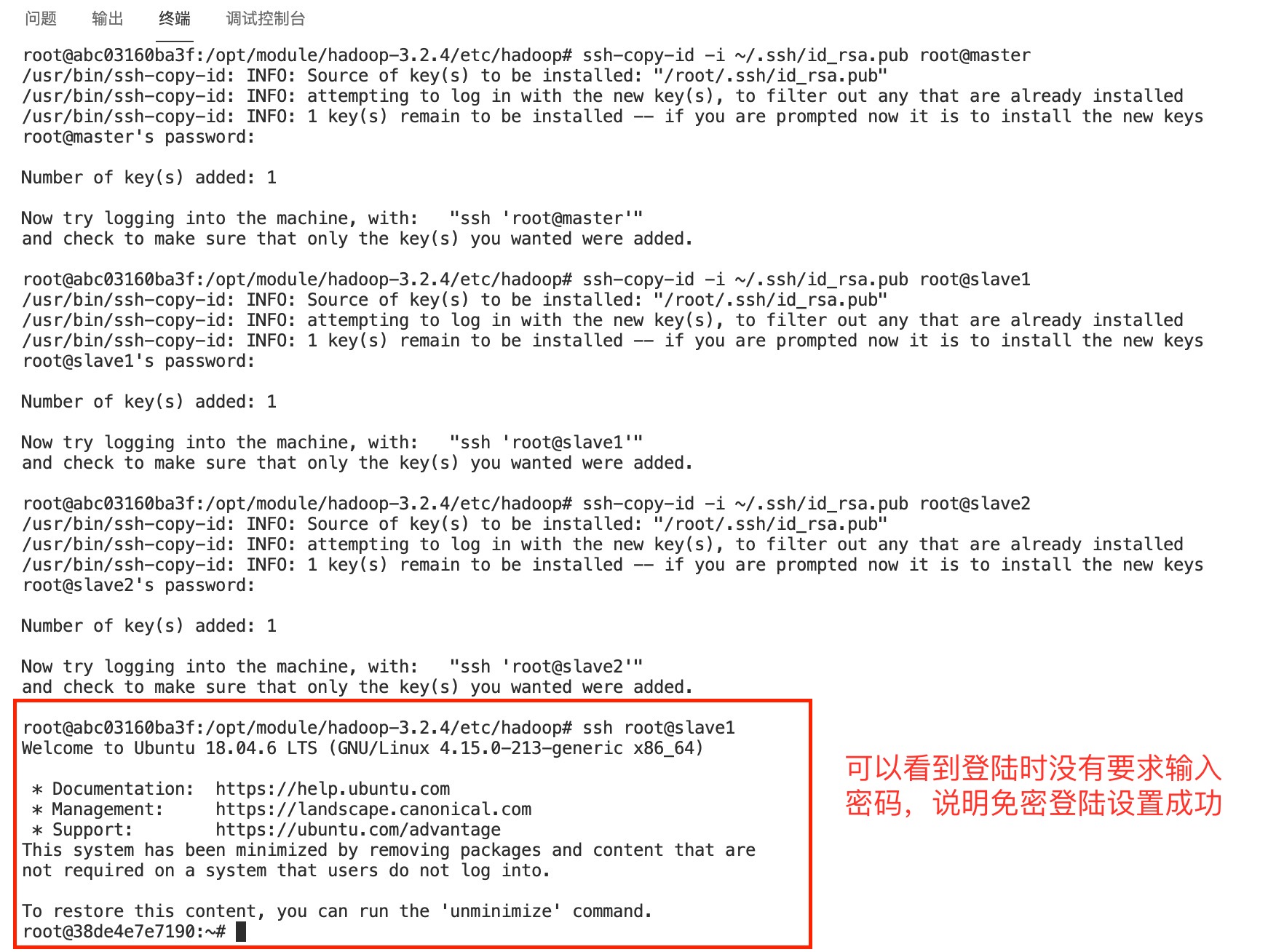
使用ssh登录成功后后,可使用 exit 命令退出ssh会话回到原先节点终端继续操作
exit
在slave1、slave2节点创建需要的文件夹
mkdir /opt/software /opt/module
用scp命令并使用绝对路径从Master复制Hadoop解压后的安装文件到slave1、slave2节点
scp -r /opt/module/hadoop-3.2.4 root@slave1:/opt/module/
scp -r /opt/module/hadoop-3.2.4 root@slave2:/opt/module/
用scp命令并使用绝对路径从Master复制JDK解压后的安装文件到slave1、slave2节点
scp -r /opt/module/jdk1.8.0_211 root@slave1:/opt/module/jdk1.8.0_211
scp -r /opt/module/jdk1.8.0_211 root@slave2:/opt/module/jdk1.8.0_211
可使用下面命令分发配置好的profile文件
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/
记得分别在slave1、slave2节点的终端执行下面的命令使profile文件生效
source /etc/profile
将全部scp复制JDK的命令截图并提交到对应的任务序号下
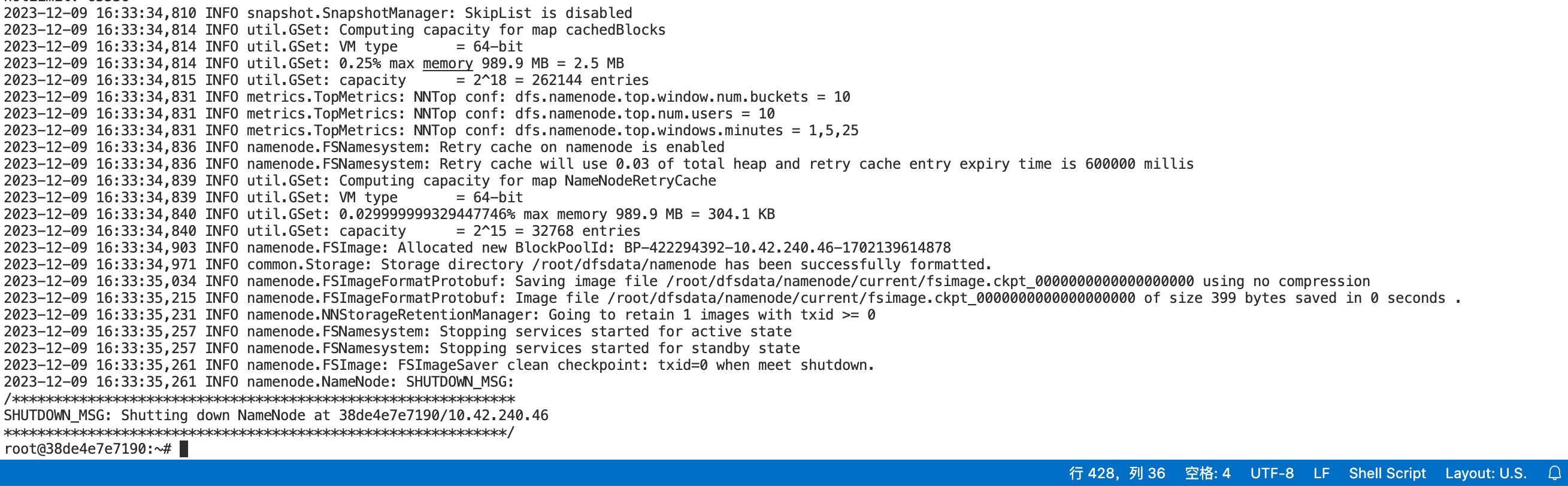
在master节点的终端使用下面的命令初始化Hadoop环境namenode
hdfs namenode -format
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。













暂无评论内容