





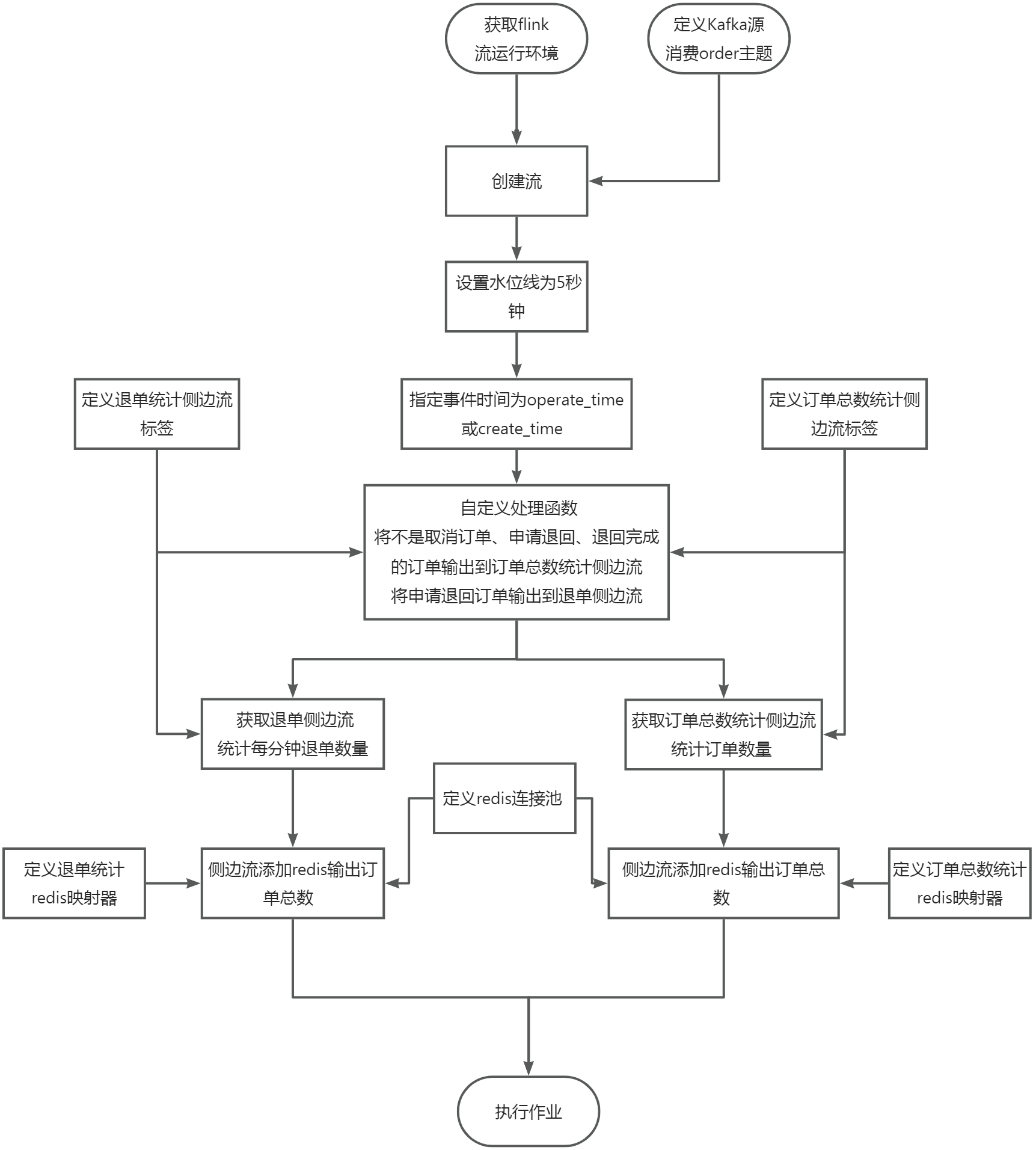
4-3.大数据国赛第2套任务D-子任务二:Flink处理Kafka中的数据
任务要求1 :1.1实现思路1.2获取Flink流运行环境1.3定义Kafka源1.4创建流1.5定义订单数量统计侧边流标签1.6设置水位线1.7设置事件时间1.8自定义处理函数1.9统计订单数量1.10创建redis连接池1.11...

4-2.Flink快速入门
api流程图批处理wordcount流处理wordcount集合sourceKafka SourceKafka SinkRedis Sink api流程图批处理wordcount在src/main/scala/org/example目录下新建WordCount.scala文件,编写批处理代...
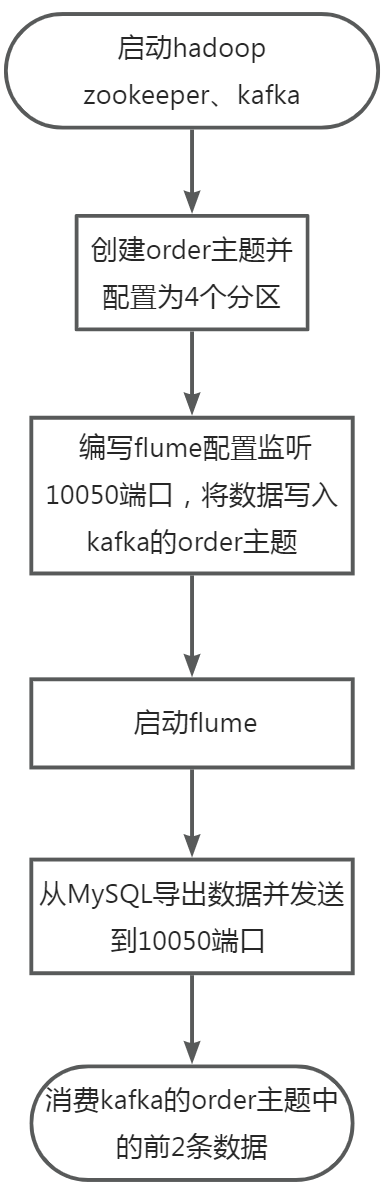
4-1.大数据国赛第2套任务D-子任务一实时数据采集
任务要求1 :1.1实现思路1.2启动Hadoop、Zookeeper、Kafka1.3创建order主题1.4编写flume配置1.5启动flume1.6编写数据生成脚本1.7运行数据生成脚本1.8.查看结果数据任务要求2 :2.1实现思路2.2启动...

3-2.大数据国赛第2套任务C-子任务二推荐系统
任务要求11.1实现思路1.2连接Spark1.3实现方式一1.4实现方式二 任务要求1根据子任务一的结果,计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户id(只考虑他俩购买过多少种相...
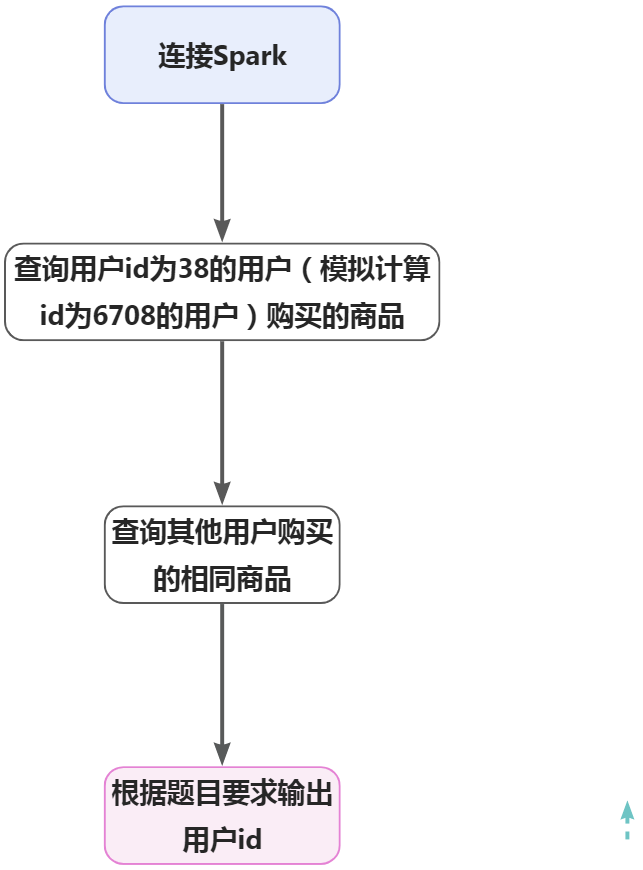
3-1.大数据国赛第2套任务C-子任务一特征工程
任务要求11.1实现思路1.2连接Spark1.3查询用户id为38的用户购买的商品id1.4查询其他用户购买的相同商品数量1.5按格式输出结果任务要求22.1实现思路2.2连接Spark2.3实现方式一2.4实现方式二 任...
![软件推荐[Windows]XMind 2024中文破解版v24.04.05171特别版-知趣](https://image.baidu.com/search/down?thumburl=https://baidu.com&url=https://tvax1.sinaimg.cn/large/008D4aBAgy1hp6xm0a056j30qo0i075h.jpg)
软件推荐[Windows]XMind 2024中文破解版v24.04.05171特别版
XMind 2024中文破解版(XMind思维导图2024)是一款风靡全球的头脑风暴和思维导图软件,为激发灵感和创意而生.在国内使用广泛,拥有强大的功能,包括思维管理,商务演示,与办公软件协同工作等功能.XMin...
![软件推荐[Android]WPS Office国际版v18.9.0 Wps安卓版破解版-知趣](https://cccimg.com/view.php/6302cf2c1a5caf5ad60a068e316c4839.webp)
软件推荐[Android]WPS Office国际版v18.9.0 Wps安卓版破解版
WPS Office for Android,金山WPS移动版,免费安卓办公软件套装,体积小、速度快。独有手机阅读模式,字体清晰翻页流畅;完美支持文字/表格/演示/PDF等51种文档格式;新版海量精美模版及高级功...

Adobe Photoshop 2024 (v25.7.0.504) 2024.04.23发布
最新版本详情:(已预激活, 下载安装后直接用) 文件名: Adobe Photoshop 2024 (v25.7.0.504) (x64) 多国语言版 版本: 2024 (v25.7.0.504) 发布日期: 2024年4月23日 软件大小: 4.42GB 简介说到图像...
![软件推荐[Windows]Bandicam中文破解版(班迪录屏) v7.1.1.2158-知趣](https://image.baidu.com/search/down?thumburl=https://baidu.com&url=https://tvax1.sinaimg.cn/large/008D4aBAgy1hoyxugk502j30h80f4q46.jpg)
软件推荐[Windows]Bandicam中文破解版(班迪录屏) v7.1.1.2158
软件介绍班迪录屏(Bandicam)是一款简单好用的录屏大师,录屏幕,录游戏,录视频的功能强大的屏幕录像软件。这是个由韩国开发的高清视频录制工具,录制的视频文件体积小,视频画质高清,支持H....
![软件推荐[Android]我的电视TV(电视直播软件) v1.7.8 免费纯净版-知趣](https://image.baidu.com/search/down?thumburl=https://baidu.com&url=https://tvax1.sinaimg.cn/large/008D4aBAgy1hozv86qbvwj30rr0fmmy6.jpg)
软件推荐[Android]我的电视TV(电视直播软件) v1.7.8 免费纯净版
我的电视APP(我的电视TV版)是一款免费无广告的智能电视及机顶盒电视直播软件APP,我的tv电视版同步央视卫视高清直播和地方卫视频道.我的电视tv电视版支持直播时移/直播预约/回看功能,高清/超清直...
![[Windows] 360清理Pro 独立提取版 v1.0.0.1081-知趣](https://attach.52pojie.cn/forum/202404/20/234004jpzku9l0089knuvl.png)
[Windows] 360清理Pro 独立提取版 v1.0.0.1081
软件介绍:360清理Pro英文名为SysCleanPro,它是360安全卫士极速版中的一个清理模块,是一款非常不错的清理工具,不需要安装360安全卫士极速版就可以单独使用。 软件特性集成【C盘清理】|【微信...

【电影】第二十条(2024)高清上线 春节档高分 张艺谋
名称:第二十条又名:正当防卫,Article 20导演:张艺谋编剧:李萌,张艺谋主演:雷佳音,马丽,赵丽颖,高叶,刘耀文,王骁,陈明昊,潘斌龙,张译,范伟,于和伟,许亚军,李乃文,蒋奇明,阿如那,杨皓宇,许静...

Epic 喜加二:《INDUSTRIA》《LISA: Definitive Edition》免费领取
Epic 本周送出的游戏是《INDUSTRIA》和《LISA: Definitive Edition》,下周送出的游戏是《兽人必须死 3》。 领取链接:《INDUSTRIA》 、《LISA: Definitive Edition》 《INDUSTRIA》游戏简...

Uncle小说:开源全网小说下载器及阅读器
Uncle小说是一款开源的小说阅读软件,旨在为用户提供一个集搜索、阅读、管理和下载于一体的综合性小说体验。软件支持文本和有声小说搜索,具备个性化的小说书架管理功能,沉浸式的阅读器和有声...

ChatGPT4.8.6无后门+卡密验证开源
为人工智能服务平台提供技术支持,全开源需要的拿走! ChatGPT卡密验证版源码是一个基于PHP7.4和MySQL5.6的聊天AI源码,它不仅支持暗黑模式、反应速度极快,而且充值方面采用后台生成卡密方式,...

