


环境说明
Hive 的配置文件位于主节点/opt/module/hive-3.1.2/conf/
Spark 任务在Yarn 上用Client 运行,方便观察日志;
ClickHouse 的jdbc 连接端口8123,用户名/密码:default/123456
命令行客户端(tcp)端口9001;
建议使用gson 解析json 数据。
任务描述
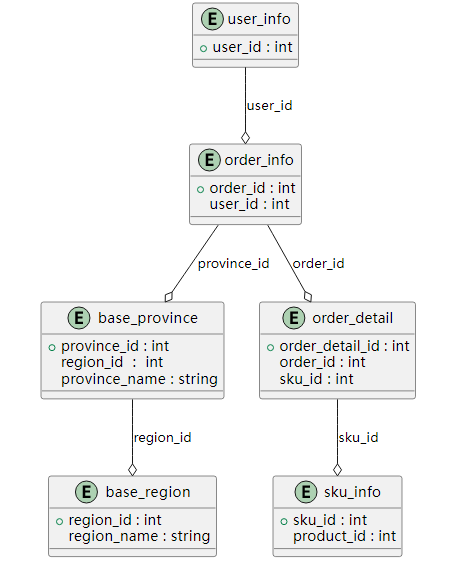
编写Scala 工程代码, 将ods 库中表order_master、order_detail、coupon_info、coupon_use、product_browse、product_info、customer_inf、customer_login_log、order_cart、customer_level_inf、customer_addr 抽取到Hive 的dwd 库中对应表中。表中有涉及到timestamp 类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。
任务分析:因为本子任务需要使用Hive的dwd 库,所以请在Hive CLI命令行下先创建好该库:
hive> create database ss2024_ds_dwd;
本任务共有12个子任务组成。单击以下链接,可快速跳转到相应的子任务部分:
子任务1
子任务1描述
1、抽取ods 库中表customer_inf 最新分区数据,并结合dim_customer_inf 最新分区现有的数据, 根据customer_id 合并数据到dwd 库中dim_customer_inf 的分区表(合并是指对dwd 层数据进行插入或修改,需修改的数据以customer_id 为合并字段,根据modified_time 排序取最新的一条),分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加 dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user 均填写“user1”。若该条记录第一次进入数仓dwd 层则dwd_insert_time、dwd_modify_time 均存当 前操作时间,并进行数据类型转换。若该数据在进入dwd 层时发生了合并修改,则dwd_insert_time 时间不变,dwd_modify_time 存当前操作时间,其余列存最新的值。使用hive cli 查询modified_time 为2022 年10 月01 日 当天的数据,查询字段为customer_id、customer_email、modified_time、dwd_insert_time、dwd_modify_time,并按照customer_id 进行升序排序,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
子任务1分析
A. 这个任务考察的技术点是upsert合并操作。那么,什么是upsert合并?可参考小白学苑博客。
Spark目前还不支持upsert操作功能。可以采用变通的方法实现,通过窗口函数Window和unionAll函数来模拟,步骤如下:
-
(1) 首先将旧表(目标表)和新表合并,使用unionAll()函数;
-
(2) 然后,使用窗口函数对记录进行分组,并基于分组为每一行分配一个行号(例如,_row_number);
-
(3) 最后,筛选DataFrame,只保留row_number = 1,因为它代表一个新记录。还要删除row_number列,因为它不再需要了。
B. 根据题意,在Hive的dwd库中应该存在着一个维度表dim_customer_inf。我们需要实现将昨天新增的用户信息(离线数据采集中的最新分区数据)抽取并合并到这个维度表中。在合并的过程中,已经存在的用户信息执行update操作,原来不存在的用户信息执行insert操作。
-
这里的问题在于,我们的练习环境是事先并没有这个dim_customer_inf维度表的。为此我们需要准备一个dim_customer_info维度表。
-
采取方式:使用hive cli手工创建该维表,并插入两条记录(1条用于修改,1条不变),然后再实现upsert过程。
-
在实际比赛中,因为比赛环境已经存在dim_customer_inf维度表,所以抽样写入的过程不必要。不过也要预防赛方环境的坑:dim_customer_info维表是什么存储格式?
准备dim_customer_inf维表
我们将按以下步骤准备dim_customer_inf维表。
1)在hive cli中,开启动态分区。
动态分区默认是没有开启。可以通过执行以下命令开启动态分区。
hive> set hive.exec.dynamic.partition.mode=nonstrict; // 分区模式,默认strict
hive> set hive.exec.dynamic.partition=true; // 开启动态分区,默认false
hive> set hive.exec.max.dynamic.partitions=1000; //最大动态分区数, 设为1000
2)使用hive cli手工创建dim_customer_inf维表。
hive> create table if not exists ss2024_ds_dwd.dim_customer_inf(
customer_inf_id bigint,
customer_id bigint,
customer_name string,
identity_card_type int,
identity_card_no string,
mobile_phone string,
customer_email string,
gender string,
customer_point bigint,
register_time timestamp,
birthday timestamp,
customer_level int,
customer_money decimal(8,2),
modified_time timestamp,
dwd_insert_user string,
dwd_insert_time timestamp,
dwd_modify_user string,
dwd_modify_time timestamp
)
partitioned by (etl_date string)
row format delimited
fields terminated by ','
stored as textfile;
3)并插入两条记录(1条用于修改,1条不变),模拟已经存在的维度表
insert into ss2024_ds_dwd.dim_customer_inf values(0,-1,"鞠桂枝",1,611325198211210472,13572811239,"songjuan@mail.com","",10564,"2032-08-16 08:48:36","1904-07-15 00:00:00",2,23675.00,"2012-08-22 03:45:36","user1","2023-12-23 09:53:08","user1","2023-12-23 09:53:08","20231225");
insert into ss2024_ds_dwd.dim_customer_inf values(0,0,"鞠桂枝",1,611325198211210472,13572811239,"songjuan@mail.com","",10564,"2032-08-16 08:48:36","1904-07-15 00:00:00",2,23675.00,"2012-08-22 03:45:36","user1","2023-12-23 09:53:08","user1","2023-12-23 09:53:08","20231225");
子任务1实现
加载ods库中customer_inf新增分区的表数据,并转换,然后与旧维表dim_customer_inf中的数据执行upsert合并。
参考实现代码如下:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob01{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 1) 旧用户维表数据
val dim_customer_inf_df = spark.sql("select * from ss2024_ds_dwd.dim_customer_inf where etl_date='20231225'")
val columns = dim_customer_inf_df.columns.map(col(_)) // 取维表列名,并将所有元素转换为Column类型
// 2) 新用户信息
val new_customer_inf_df = spark
// 抽取
.sql("select * from ss2024_ds_ods.customer_inf where etl_date='20231225'")
// 转换
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.select(columns: _*) // 校正列顺序,以便列对齐
// 3)执行upsert合并
// (1) 合并两个数据集
val unioned_df = dim_customer_inf_df.union(new_customer_inf_df)
// (2) 为每一行分配一个行号(_row_number)。可以使用窗口函数对记录进行分组和分区。
// 定义窗口规范
val w1 = Window.partitionBy("customer_id").orderBy(col("modified_time").desc)
val w2 = Window.partitionBy("customer_id")
val unioned_rank_df = unioned_df
.withColumn("_row_number", row_number().over(w1))
.withColumn("dwd_insert_time",min("dwd_insert_time").over(w2)) // insert_time,总是取最小那个值,dwd_insert_time 时间不变
.withColumn("dwd_modify_time",max("dwd_modify_time").over(w2)) // modify_time,总是取最大那个值,dwd_modify_time 存当前操作时间
// (3) 筛选DataFrame,只保留_row_number = 1。还要删除_row_number列,因为它不再需要了。
val merged = unioned_rank_df.where("_row_number = 1").drop("_row_number")
// 4)写入Hive数仓DWD中
// (1) 先将结果保存在临时表中
merged
.write
.mode("overwrite")
.saveAsTable("tmp_dim_customer_inf")
// (2) 再读取临时表覆盖结果表
spark
.table("tmp_dim_customer_inf")
.write
.mode("overwrite")
.insertInto("ss2024_ds_dwd.dim_customer_inf")
// 删除临时表
spark.sql("drop table tmp_dim_customer_inf")
}
}
子任务2
子任务1描述
2、抽取ods 库中表coupon_info 最新分区数据,并结合dim_coupon_info 最新分区现有的数据,根据coupon_id 合并数据到dwd 库中dim_coupon_info 的分区表(合并是指对dwd 层数据进行插入或修改,需修改的数据以coupon_id为合并字段,根据modified_time 排序取最新的一条),分区字段为etl_date且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time 四列, 其中dwd_insert_user、dwd_modify_user 均填写“user1”。若该条记录第一次进入数仓dwd 层则dwd_insert_time、dwd_modify_time 均存当前操作时间,并进行数据类型转换。若该数据在进入dwd 层时发生了合并修改,则dwd_insert_time 时间不变,dwd_modify_time 存当前操作时间,其余列存 最新的值。使用hive cli 执行show partitions dwd.dim_coupon_info 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
子任务2分析
该子任务与子任务1类似。同样地,我们需要先准备好一个dim_coupon_info维表。
我们将在该维表中创建两条新的数据记录:一条的coupon_id也为1,但改动其他几个字段的值,用于演示update;另一条的coupon_id设为0,用于演示未被update的数据。
准备dim_coupon_info维表
我们将按以下步骤准备dim_coupon_info维表。
1)在hive cli中,开启动态分区。
动态分区默认是没有开启。可以通过执行以下命令开启动态分区。
hive> set hive.exec.dynamic.partition.mode=nonstrict; // 分区模式,默认strict
hive> set hive.exec.dynamic.partition=true; // 开启动态分区,默认false
hive> set hive.exec.max.dynamic.partitions=1000; //最大动态分区数, 设为1000
2)使用hive cli手工创建dim_coupon_info维表。
hive> create table if not exists ss2024_ds_dwd.dim_coupon_info(
coupon_id bigint,
coupon_name string,
coupon_type int,
condition_amount bigint,
condition_num bigint,
activity_id string,
benefit_amount decimal(8,2),
benefit_discount decimal(8,2),
modified_time timestamp,
dwd_insert_user string,
dwd_insert_time timestamp,
dwd_modify_user string,
dwd_modify_time timestamp
)
partitioned by (etl_date string)
row format delimited
fields terminated by ','
stored as textfile;
3)并插入两条记录(1条用于修改,1条不变),模拟已经存在的维度表
insert into ss2024_ds_dwd.dim_coupon_info values(0,"11折优惠券",11,11000,3,"6569962031230",0.00,0.10,"2022-09-09 06:23:07","user1","2023-12-23 09:53:08","user1","2023-12-23 09:53:08","20231225");
insert into ss2024_ds_dwd.dim_coupon_info values(1,"11折优惠券",11,11000,3,"6569962031230",0.00,0.10,"2022-09-09 06:23:07","user1","2023-12-23 09:53:08","user1","2023-12-23 09:53:08","20231225");
子任务2实现
加载ods库中coupon_info新增分区的表数据,并转换,然后与旧维表dim_coupon_info中的数据执行upsert合并。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob02{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 1) 旧用户维表数据
val dim_coupon_info_df = spark.sql("select * from ss2024_ds_dwd.dim_coupon_info where etl_date='20231225'")
// 取维表列名,并将所有元素转换为Column类型
val columns = dim_coupon_info_df.columns.map(col(_))
// 2) 新用户信息
val new_coupon_info_df = spark
// 抽取
.sql("select * from ss2024_ds_ods.coupon_info where etl_date='20231225'")
// 转换
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.select(columns: _*) // 校正列顺序,以便列对齐
// 3)执行upsert合并
// (1) 合并两个数据集
val unioned_df = dim_coupon_info_df.union(new_coupon_info_df)
// (2) 为每一行分配一个行号(_row_number)。可以使用窗口函数对记录进行分组和分区
// 定义窗口规范
val w1 = Window.partitionBy("coupon_id").orderBy($"modified_time".desc)
val w2 = Window.partitionBy("coupon_id")
val unioned_rank_df = unioned_df
.withColumn("_row_number", row_number().over(w1)) // 分配行号
.withColumn("dwd_insert_time",min("dwd_insert_time").over(w2)) // insert_time,总是取最小那个值,dwd_insert_time 时间不变
.withColumn("dwd_modify_time",max("dwd_modify_time").over(w2)) // modify_time,总是取最大那个值,dwd_modify_time 存当前操作时间
// (3) 筛选DataFrame,只保留_row_number = 1。还要删除_row_number列,因为它不再需要了。
val merged = unioned_rank_df.where("_row_number = 1").drop("_row_number")
// 4)写入Hive数仓DWD中
// (1) 先将结果保存在临时表中
merged
.write
.mode("overwrite")
.saveAsTable("tmp_dim_coupon_info")
// (2) 再读取临时表覆盖结果表
spark
.table("tmp_dim_coupon_info")
.write
.mode("overwrite")
.insertInto("ss2024_ds_dwd.dim_coupon_info")
// 删除临时表
spark.sql("drop table tmp_dim_coupon_info")
}
}
子任务3
子任务3描述
3、抽取ods 库中表product_info 最新分区的数据,并结合dim_product_info最新分区现有的数据, 根据product_core 合并数据到dwd 库中 dim_product_info 的分区表(合并是指对dwd 层数据进行插入或修改,需修改的数据以product_core 为合并字段,根据modified_time 排序取最新的 一条),分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time 四列,其中dwd_insert_user、dwd_modify_user 均填写“user1”。若该条记录第一次进入数仓dwd 层则dwd_insert_time、dwd_modify_time 均存当 前操作时间,并进行数据类型转换。若该数据在进入dwd 层时发生了合并修改,则dwd_insert_time 时间不变,dwd_modify_time 存当前操作时间,其 余列存最新的值。使用hive cli 执行show partitionsdwd.dim_product_info 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
该子任务与前两个子任务类似。同样地,我们需要先准备好一个dim_product_info维表。
我们将在该维表中创建两条新的数据记录:一条的product_core也为”1571120092163″,但改动其他几个字段的值,用于演示update;另一条的coupon_id设为”1112223334444″,用于演示未被update的数据。
准备dim_product_info维表
我们将按以下步骤准备dim_product_info维表。
1)在hive cli中,开启动态分区。
动态分区默认是没有开启。可以通过执行以下命令开启动态分区。
hive> set hive.exec.dynamic.partition.mode=nonstrict; // 分区模式,默认strict
hive> set hive.exec.dynamic.partition=true; // 开启动态分区,默认false
hive> set hive.exec.max.dynamic.partitions=1000; //最大动态分区数, 设为1000
2)使用hive cli手工创建dim_product_info维表。
hive> create table if not exists ss2024_ds_dwd.dim_product_info(
product_id bigint,
product_core string,
product_name string,
bar_code string,
brand_id bigint,
one_category_id int,
two_category_id int,
three_category_id int,
supplier_id bigint,
price decimal(8,2),
average_cost decimal(18,2),
publish_status int,
audit_status int,
weight float,
length float,
height float,
width float,
color_type string,
production_date timestamp,
shelf_life bigint,
descript string,
indate timestamp,
modified_time timestamp,
dwd_insert_user string,
dwd_insert_time timestamp,
dwd_modify_user string,
dwd_modify_time timestamp
)
partitioned by (etl_date string)
row format delimited
fields terminated by ','
stored as textfile;
3)并插入两条记录(1条用于修改,1条不变),模拟已经存在的维度表
insert into ss2024_ds_dwd.dim_product_info values(0,"1112223334444","这是一条测试语句,不会被修改","1080918117235",7,1,5,8,792,983.47,123.82,0,1,6.11,5.35,2.06,5.21,"yellow","2022-01-16 00:51:05",36,"描述信息","2022-08-28 05:13:45","2002-09-04 22:56:45","user1","2023-12-23 09:53:08","user1","2023-12-23 09:53:08","20231225");
insert into ss2024_ds_dwd.dim_product_info values(0,"1571120092163","这是一条测试语句,但是会被修改","1080918117235",7,1,5,8,792,983.47,123.82,0,1,6.11,5.35,2.06,5.21,"yellow","2022-01-16 00:51:05",36,"描述信息","2022-08-28 05:13:45","2002-09-04 22:56:45","user1","2023-12-23 09:53:08","user1","2023-12-23 09:53:08","20231225");
子任务3实现
加载ods库中product_info新增分区的表数据,并转换,然后与旧维表dim_product_info中的数据执行upsert合并。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob03{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 1) 旧用户维表数据
val dim_product_info_df = spark.sql("select * from ss2024_ds_dwd.dim_product_info where etl_date='20231225'")
// 取维表列名,并将所有元素转换为Column类型
val columns = dim_product_info_df.columns.map(col(_))
// 2) 新用户信息
val new_product_info_df = spark
// 抽取
.sql("select * from ss2024_ds_ods.product_info where etl_date='20231225'")
// 转换
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.select(columns: _*) // 校正列顺序,以便列对齐
// 3)执行upsert合并
// (1) 合并两个数据集
val unioned_df = dim_product_info_df.union(new_product_info_df)
// (2) 为每一行分配一个行号(_row_number)。可以使用窗口函数对记录进行分组和分区。
// 定义窗口规范
val w1 = Window.partitionBy("product_core").orderBy($"modified_time".desc)
val w2 = Window.partitionBy("product_core")
val unioned_rank_df = unioned_df
.withColumn("_row_number", row_number().over(w1)) // 分配行号
.withColumn("dwd_insert_time",min("dwd_insert_time").over(w2)) // insert_time,总是取最小那个值,dwd_insert_time 时间不变
.withColumn("dwd_modify_time",max("dwd_modify_time").over(w2)) // modify_time,总是取最大那个值,dwd_modify_time 存当前操作时间
// (3) 筛选DataFrame,只保留_row_number = 1。还要删除_row_number列,因为它不再需要了。
val merged = unioned_rank_df.where("_row_number = 1").drop("_row_number")
// 4)写入Hive数仓DWD中
// (1) 先将结果保存在临时表中
merged
.write
.mode("overwrite")
.saveAsTable("tmp_dim_product_info")
// (2) 再读取临时表覆盖结果表
spark
.table("tmp_dim_product_info")
.write
.mode("overwrite")
.insertInto("ss2024_ds_dwd.dim_product_info")
// 删除临时表
spark.sql("drop table tmp_dim_product_info")
}
}
子任务4
子任务4描述
4、抽取ods 库中表order_master 最新分区的数据, 并结合HBase 中order_master_offline 表中的数据合并抽取到dwd 库中fact_order_master 的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time 四列, 其中dwd_insert_user 、dwd_modify_user 均填写“ user1 ” ,dwd_insert_time、dwd_modify_time 均填写当前操作时间(年月日必须是今 天,时分秒只需在比赛时间范围内即可),抽取HBase 中的数据时,只抽取2022 年10 月01 日的数据(以rowkey 为准),并进行数据类型转换。使用 hive cli 查询modified_time 为2022 年10 月01 日当天的数据,查询字段为order_id、order_sn、shipping_user、create_time、shipping_time, 并按照order_id 进行升序排序, 将结果截图复制粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
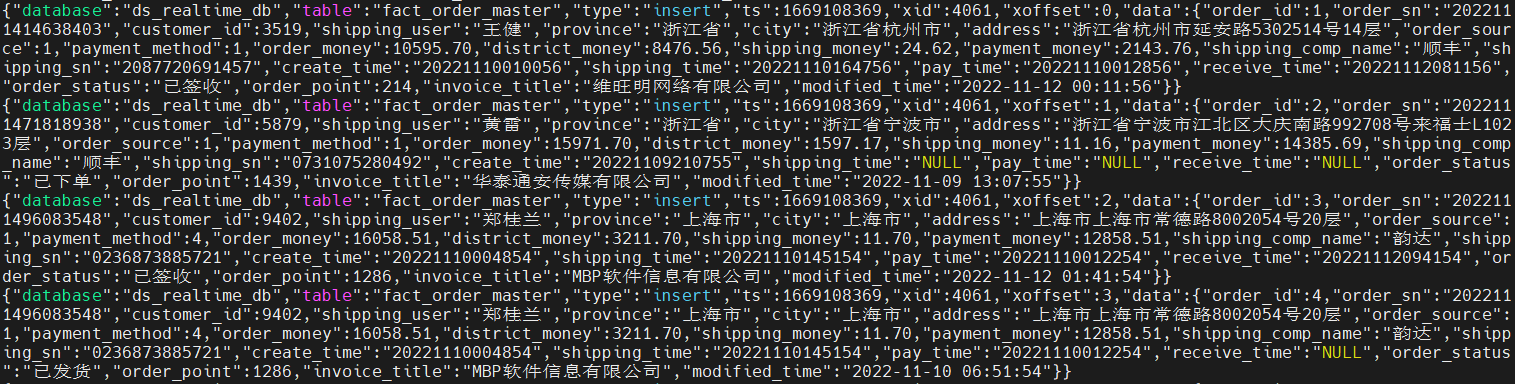
ods: order_master_offline 数据结构如下:
| 字段 | 类型 | 中文含义(和MySQL中相同) | 备注 |
|---|---|---|---|
| rowkey | string | rowkey | 随机数(0-9)+yyyyMMddHHmmssSSS(date 的格式) |
| Info | 列族名 | ||
| order_id | int | ||
| order_sn | string | ||
| customer_id | int | ||
| shipping_user | string | ||
| province | string | ||
| city | string | ||
| address | string | ||
| order_source | int | ||
| payment_method | int | ||
| order_money | double | ||
| district_money | double | ||
| shipping_money | double | ||
| payment_money | double | ||
| shipping_comp_name | string | ||
| shipping_sn | string | ||
| create_time | string | ||
| shipping_time | string | ||
| pay_time | string | ||
| receive_time | string | ||
| order_status | string | ||
| order_point | int | ||
| invoice_title | string | ||
| modified_time | string |
子任务4分析
该子任务要求合并离线链路数据和实时链路数据,涉及到如何使用Spark读取HBase表数据。可参考小白学苑的教程《》。
根据题意,比赛时环境中应该存在一个ods:order_master_offline的HBase表。但在我们的练习环境中并没有此表,因此我们需要在HBase中准备好一个名为ods:order_master_offline的HBase表,并准备一条的order_id=0的记录,用于代表实时链路的数据。
准备HBase表及插入表数据
首先,创建HBase命名空间ods(如果没有该命名空间的话):
hbase shell> create_namespace 'ods'
然后执行如下命令和脚本,以完成HBase表的创建和数据插入:
# hbase shell ./do_order_master.dat
子任务4实现
编写一个Spark程序,分别从Hive ODS加载离线数据,从HBase中加载实时链路存量数据,然后合并这两个数据集,并根据任务要求进行适当的数据类型转换和数据处理。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.filter._
import org.apache.hadoop.hbase.CompareOperator
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
object CleaningJob04{
// case class
case class OrderMaster(
order_id: String, // Long
order_sn: String,
customer_id: String, // Long
shipping_user: String,
province: String,
city: String,
address: String,
order_source: String,
payment_method: String,
order_money: String,
district_money: String,
shipping_money: String,
payment_money: String,
shipping_comp_name: String,
shipping_sn: String,
create_time: String,
shipping_time: String,
pay_time: String,
receive_time: String,
order_status: String,
order_point: String,
invoice_title: String,
modified_time: String
)
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 1)从Hive ODS读取离线订单数据
val hive_ods_order_master = spark.sql("select * from ss2024_ds_ods.order_master")
// 2)从HBase表中读取数据到DataFrame中
/*
需转换的列:
- String => Long:order_id, customer_id, order_point
- String => Int: order_source, payment_methond
- String => Decimal(8,2):order_money, district_money, shipping_money, payment_money
- String => Timestamp:modified_time
- 增加分区列:etl_date="20231225"
*/
val hbase_ods_order_master = readHBase(spark)
// String => Long
.withColumn("order_id", col("order_id").cast("long"))
.withColumn("customer_id", col("customer_id").cast("long"))
.withColumn("order_point", col("order_point").cast("long"))
// String => Int
.withColumn("order_source", col("order_source").cast("int"))
.withColumn("payment_method", col("payment_method").cast("int"))
// String => Decimal(8,2)
.withColumn("order_money", col("order_money").cast("decimal(8,2)"))
.withColumn("district_money", col("district_money").cast("decimal(8,2)"))
.withColumn("shipping_money", col("shipping_money").cast("decimal(8,2)"))
.withColumn("payment_money", col("payment_money").cast("decimal(8,2)"))
// String => Timestamp
.withColumn("modified_time", col("modified_time").cast("timestamp"))
// 增加分区列
.withColumn("etl_date",lit("20231225"))
// 3)合并存量数据和增量数据,写入Hive DWD层
val fact_order_master = hive_ods_order_master
// 垂直合并
.union(hbase_ods_order_master)
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// 4)写入Hive DWD层
// 如果已存在有fact_order_master表,则与前面的示例相同,使用InsertInto()方法
// 这里我们假设没有fact_order_master表,使用saveAsTable()方法
println("正在写入 Hive DWD层 ...")
fact_order_master.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.fact_order_master") // 保存到Hive表
println("已完成写入 Hive DWD层")
}
/* 创建scan过滤, 过滤出rowkey包含'20221001'内容的行
* 假设rowkey格式为:创建日期_发布日期_ID_TITLE
* 目标:查找 rowkey中包含 20221001 的数据
* 使用行过滤器:new RowFilter(CompareOp.EQUAL , new SubstringComparator("20221001"))
* 返回 org.apache.hadoop.hbase.client.Scan
*/
def getScan: Scan = {
// 创建Scan
val scan = new Scan()
// 指定行过滤器(行键必须包含子字符串"20221001")
val rowFilter = new RowFilter(CompareOperator.EQUAL, new SubstringComparator("20221001"))
// scan 设置过滤器
scan.setFilter(rowFilter)
scan.withStartRow(Bytes.toBytes("0+20221001000000000")) // 起始行键
scan.withStopRow(Bytes.toBytes("9+20221001235959999")) // 结束行键
scan
}
// 自定义方法:使用 newAPIHadoopRDD 读取数据
def readHBase(spark:SparkSession):DataFrame = {
// 1) 创建HbaseConfiguration配置信息
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum", "192.168.190.139") //设置zooKeeper集群地址,也可以通过将hbase-site.xml拷贝到resources目录下
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181") //设置zookeeper连接端口,默认2181
hbaseConf.set("hbase.master", "192.168.190.139:16000") // 设置HBase HMaster
// 设置从HBase哪张表读取数据
val tablename = "ods:order_master_offline" // 要读取的hbase表名
hbaseConf.set(TableInputFormat.INPUT_TABLE, tablename) // 注意:读取时使用TableInputFormat
// 2)添加filter => TableMapReduceUtil.convertScanToString(getScan)
hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(getScan))
// 3)调用SparkContext中newAPIHadoopRDD读取表中的数据,构建RDD
val resultRDD: RDD[(ImmutableBytesWritable, Result)] = spark.sparkContext.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
// 4)对获取的值进行过滤,并转换为DataFrame返回
import spark.implicits._
resultRDD
.map { t =>
val result = t._2 // 获得Result
val map: collection.mutable.Map[String, String] = collection.mutable.Map() // 存储列限定符和列值
for (cell <- result.rawCells()) {
val colum = Bytes.toString(CellUtil.cloneQualifier(cell)) // 列限定符
val value = Bytes.toString(CellUtil.cloneValue(cell)) // 列值
map.put(colum, value)
}
// 构造为OrderMaster对象实例
OrderMaster(order_id=map.get("order_id").get,
order_sn=map.get("order_sn").get,
customer_id=map.get("customer_id").get,
shipping_user=map.get("shipping_user").get,
province=map.get("province").get,
city=map.get("city").get,
address=map.get("address").get,
order_source=map.get("order_source").get,
payment_method=map.get("payment_method").get,
order_money=map.get("order_money").get,
district_money=map.get("district_money").get,
shipping_money=map.get("shipping_money").get,
payment_money=map.get("payment_money").get,
shipping_comp_name=map.get("shipping_comp_name").get,
shipping_sn=map.get("shipping_sn").get,
create_time=map.get("create_time").get,
shipping_time=map.get("shipping_time").get,
pay_time=map.get("pay_time").get,
receive_time=map.get("receive_time").get,
order_status=map.get("order_status").get,
order_point=map.get("order_point").get,
invoice_title=map.get("invoice_title").get,
modified_time=map.get("modified_time").get
)
}
// 转换为DataFrame
.toDF()
}
}
子任务5
子任务5描述
5、抽取ods 库中表order_detail 表最新分区的数据, 并结合HBase 中order_detail_offline 表中的数据合并抽取到dwd 库中fact_order_detail的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列, 其中dwd_insert_user 、dwd_modify_user 均填写“ user1 ” ,dwd_insert_time、dwd_modify_time 均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),抽取HBase 中的数据时,只抽取2022 年10 月01 日的数据(以rowkey 为准),并进行数据类型转换。使用hive cli 查询modified_time 为2022 年10 月01 日当天的数据,查询字段为order_detail_id 、order_sn 、product_name 、create_time , 并按照order_detail_id 进行升序排序,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
ods:order_detail_offline 数据结构如下:
| 字段 | 类型 | 中文含义(和MySQL中相同) | 备注 |
|---|---|---|---|
| rowkey | string | rowkey | 随机数(0-9)+yyyyMMddHHmmssSSS(date 的格式) |
| Info | 列族名 | ||
| order_detail_id | int | ||
| order_sn | string | ||
| product_id | int | ||
| product_name | string | ||
| product_cnt | int | ||
| product_price | double | ||
| average_cost | double | ||
| weight | double | ||
| fee_money | double | ||
| w_id | int | ||
| create_time | string | ||
| modified_time | string |
子任务5分析
该子任务要求合并离线链路数据和实时链路数据,涉及到如何使用Spark读取HBase表数据。可参考小白学苑的教程《》。
根据题意,比赛时环境中应该存在一个ods:order_detail_offline的HBase表。但在我们的练习环境中并没有此表,因此我们需要在HBase中准备好一个名为ods:order_detail_offline的HBase表,并准备一条的order_detail_id=0的记录,用于代表实时链路的数据。
准备HBase表及插入表数据
首先,创建HBase命名空间ods(如果没有该命名空间的话):
hbase shell> create_namespace 'ods'
然后执行如下命令和脚本,以完成HBase表的创建和数据插入:
# hbase shell ./do_order_detail.dat
子任务5实现
编写一个Spark程序,分别从Hive ODS加载离线数据,从HBase中加载实时链路存量数据,然后合并这两个数据集,并根据任务要求进行适当的数据类型转换和数据处理。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.filter._
import org.apache.hadoop.hbase.CompareOperator
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
object CleaningJob05{
// case class
case class OrderDetail(
order_detail_id: String,
order_sn: String,
product_id: String,
product_name: String,
product_cnt: String,
product_price: String,
average_cost: String,
weight: String,
fee_money: String,
w_id: String,
create_time: String,
modified_time: String
)
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 1)从Hive ODS读取离线订单数据
val hive_ods_order_detail = spark.sql("select * from ss2024_ds_ods.order_detail")
// 2)从HBase表中读取数据到DataFrame中
/*
需转换的列:
- String => Long:order_detail_id, product_id, product_cnt, w_id
- String => Float: weight
- String => Decimal(8,2):product_price, average_cost, fee_money
- String => Timestamp:modified_time
- 增加分区列:etl_date="20231225"
*/
val hbase_ods_order_detail = readHBase(spark)
// String => Long
.withColumn("order_detail_id", col("order_detail_id").cast("long"))
.withColumn("product_id", col("product_id").cast("long"))
.withColumn("product_cnt", col("product_cnt").cast("long"))
.withColumn("w_id", col("w_id").cast("long"))
// String => Float
.withColumn("weight", col("weight").cast("float"))
// String => Decimal(8,2)
.withColumn("product_price", col("product_price").cast("decimal(8,2)"))
.withColumn("average_cost", col("average_cost").cast("decimal(8,2)"))
.withColumn("fee_money", col("fee_money").cast("decimal(8,2)"))
// String => Timestamp
.withColumn("modified_time", col("modified_time").cast("timestamp"))
// 增加分区列
.withColumn("etl_date",lit("20231225"))
// 3)合并存量数据和增量数据,写入Hive DWD层
val fact_order_detail = hive_ods_order_detail
// 垂直合并
.union(hbase_ods_order_detail)
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// 4)写入Hive DWD层
// 如果已存在有fact_order_detail表,则与前面的示例相同,使用InsertInto()方法
// 这里我们假设没有fact_order_detail表,使用saveAsTable()方法
println("正在写入 Hive DWD层 ...")
fact_order_detail.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.fact_order_detail") // 保存到Hive表
println("已完成写入 Hive DWD层")
}
/* 创建scan过滤, 过滤出rowkey包含'20221001'内容的行
* 假设rowkey格式为:创建日期_发布日期_ID_TITLE
* 目标:查找 rowkey中包含 20221001 的数据
* 使用行过滤器:new RowFilter(CompareOp.EQUAL , new SubstringComparator("20221001"))
* 返回 org.apache.hadoop.hbase.client.Scan
*/
def getScan: Scan = {
// 创建Scan
val scan = new Scan()
// 指定行过滤器(行键必须包含子字符串"20221001")
val rowFilter = new RowFilter(CompareOperator.EQUAL, new SubstringComparator("20221001"))
// scan 设置过滤器
scan.setFilter(rowFilter)
scan.withStartRow(Bytes.toBytes("0+20221001000000000")) // 起始行键
scan.withStopRow(Bytes.toBytes("9+20221001235959999")) // 结束行键
scan
}
// 自定义方法:使用 newAPIHadoopRDD 读取数据
def readHBase(spark:SparkSession):DataFrame = {
// 1) 创建HbaseConfiguration配置信息
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum", "192.168.190.139") //设置zooKeeper集群地址,也可以通过将hbase-site.xml拷贝到resources目录下
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181") //设置zookeeper连接端口,默认2181
hbaseConf.set("hbase.master", "192.168.190.139:16000") // 设置HBase HMaster
// 设置从HBase哪张表读取数据
val tablename = "ods:order_detail_offline" // 要读取的hbase表名
hbaseConf.set(TableInputFormat.INPUT_TABLE, tablename) // 注意:读取时使用TableInputFormat
// 2)添加filter => TableMapReduceUtil.convertScanToString(getScan)
hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(getScan))
// 3)调用SparkContext中newAPIHadoopRDD读取表中的数据,构建RDD
val resultRDD: RDD[(ImmutableBytesWritable, Result)] = spark.sparkContext.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
// 4)对获取的值进行过滤,并转换为DataFrame返回
import spark.implicits._
resultRDD
.map { t =>
val result = t._2 // 获得Result
val map: collection.mutable.Map[String, String] = collection.mutable.Map() // 存储列限定符和列值
for (cell <- result.rawCells()) {
val colum = Bytes.toString(CellUtil.cloneQualifier(cell)) // 列限定符
val value = Bytes.toString(CellUtil.cloneValue(cell)) // 列值
map.put(colum, value)
}
// 构造为OrderDetail对象实例
OrderDetail(order_detail_id=map.get("order_detail_id").get,
order_sn=map.get("order_sn").get,
product_id=map.get("product_id").get,
product_name=map.get("product_name").get,
product_cnt=map.get("product_cnt").get,
product_price=map.get("product_price").get,
average_cost=map.get("average_cost").get,
weight=map.get("weight").get,
fee_money=map.get("fee_money").get,
w_id=map.get("w_id").get,
create_time=map.get("create_time").get,
modified_time=map.get("modified_time").get
)
}
// 转换为DataFrame
.toDF()
}
}
子任务6
子任务6描述
6、抽取ods 库中表coupon_use 最新分区的数据到dwd 库中fact_coupon_use的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列, 其中dwd_insert_user 、dwd_modify_user 均填写“ user1 ” ,dwd_insert_time、dwd_modify_time 均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),并进行数据类型转换。使用hive cli 执行show partitions dwd.fact_coupon_use 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
子任务6分析
这个任务需求中没有明确说是增量抽取还是全量抽取,大家在比赛时需要去探索了解。这里我们假设它是全量抽取。
子任务6实现
编写Spark代码,实现数据的转换,并写入到Hive的DWD层。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob06{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 从Hive ODS读取离线数据,转换,写入到Hive DWD层
spark.sql("select * from ss2024_ds_ods.coupon_use where etl_date='20231225'")
//.show
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// .show
.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.fact_coupon_use") // 保存到Hive表
}
}
子任务7
子任务7描述
7、抽取ods 库中表customer_login_log 最新分区的数据到dwd 库中log_customer_login 的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等, 并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time 四列, 其中dwd_insert_user、dwd_modify_user 均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可) , 并进行数据类型转换。使用hive cli 执行show partitions dwd.log_customer_login 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
子任务7分析
这个任务需求中没有明确说是增量抽取还是全量抽取,大家在比赛时需要去探索了解。这里我们假设它是全量抽取。
子任务7实现
编写Spark代码,实现数据的转换,并写入到Hive的DWD层。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob07{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 从Hive ODS读取离线数据,转换,写入到Hive DWD层
spark.sql("select * from ss2024_ds_ods.customer_login_log where etl_date='20231225'")
//.show
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// .show
.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.log_customer_login") // 保存到Hive表
}
}
子任务8
子任务8描述
8、抽取ods 库中表order_cart 最新分区的数据到dwd 库中fact_order_cart的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列, 其中dwd_insert_user 、dwd_modify_user 均填写“ user1 ” ,dwd_insert_time、dwd_modify_time 均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),并进行数据类型转换。使用hive cli 执行show partitions dwd.fact_order_cart 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
子任务8分析
这个任务需求中没有明确说是增量抽取还是全量抽取,大家在比赛时需要去探索了解。这里我们假设它是全量抽取。
子任务8实现
编写Spark代码,实现数据的转换,并写入到Hive的DWD层。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob08{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 从Hive ODS读取离线数据,转换,写入到Hive DWD层
spark.sql("select * from ss2024_ds_ods.order_cart where etl_date='20231225'")
//.show
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// .show
.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.fact_order_cart") // 保存到Hive表
}
}
子任务9
子任务9描述
9、抽取ods 库中表product_browse 最新分区的数据, 并结合HBase 中product_browse_offline 表中的数据合并抽取到dwd 库中log_product_browse 的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等, 并添加dwd_insert_user 、dwd_insert_time 、dwd_modify_user 、dwd_modify_time 四列, 其中dwd_insert_user 、dwd_modify_user 均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),抽取HBase 中的数据时,只抽取2022 年10 月01 日的数据(以rowkey为准),并进行数据类型转换。使用hive cli 查询modified_time 为2022年10 月01 日当天的数据,查询字段为log_id、product_id、order_sn、modified_time,并按照log_id 进行升序排序,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
ods:product_browse_offline 数据结构如下:
| 字段 | 类型 | 中文含义(和MySQL中相同) | 备注 |
|---|---|---|---|
| rowkey | string | rowkey | 随机数(0-9)+MMddHHmmssSSS |
| Info | 列族名 | ||
| log_id | int | ||
| product_id | int | ||
| customer_id | string | ||
| gen_order | int | ||
| order_sn | string | ||
| modified_time | double |
子任务9分析
该子任务要求合并离线链路数据和实时链路数据,涉及到如何使用Spark读取HBase表数据。可参考小白学苑的教程《》。
根据题意,比赛时环境中应该存在一个ods:product_browse_offline的HBase表。但在我们的练习环境中并没有此表,因此我们需要在HBase中准备好一个名为ods:product_browse_offline的HBase表,并准备一条的log_id=0的记录,用于代表实时链路的数据。
准备HBase表及插入表数据
首先,创建HBase命名空间ods(如果没有该命名空间的话):
hbase shell> create_namespace 'ods'
然后执行如下命令和脚本,以完成HBase表的创建和数据插入:
# hbase shell ./do_product_browse.dat
子任务9实现
编写一个Spark程序,分别从Hive ODS加载离线数据,从HBase中加载实时链路存量数据,然后合并这两个数据集,并根据任务要求进行适当的数据类型转换和数据处理。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.filter._
import org.apache.hadoop.hbase.CompareOperator
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.serializer.KryoSerializer
import org.apache.spark.sql._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
object CleaningJob09{
// case class
case class ProductBrowse(
log_id: String,
product_id: String,
customer_id: String,
gen_order: String,
order_sn: String,
modified_time: String
)
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 1)从Hive ODS读取离线订单数据
val hive_ods_product_browse = spark.sql("select * from ss2024_ds_ods.product_browse")
// 2)从HBase表中读取数据到DataFrame中
/*
需转换的列:
- String => Long:log_id, product_id, customer_id, gen_order
- String => Timestamp:modified_time
- 增加分区列:etl_date="20231225"
*/
val hbase_ods_product_browse = readHBase(spark)
// String => Long
.withColumn("log_id", col("log_id").cast("long"))
.withColumn("product_id", col("product_id").cast("long"))
.withColumn("customer_id", col("customer_id").cast("long"))
.withColumn("gen_order", col("gen_order").cast("long"))
// String => Timestamp
.withColumn("modified_time", col("modified_time").cast("timestamp"))
// 增加分区列
.withColumn("etl_date",lit("20231225"))
// 3)合并存量数据和增量数据,写入Hive DWD层
val log_product_browse = hive_ods_product_browse
// 垂直合并
.union(hbase_ods_product_browse)
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// 4)写入Hive DWD层
// 如果已存在有log_product_browse表,则与前面的示例相同,使用InsertInto()方法
// 这里我们假设没有log_product_browse表,使用saveAsTable()方法
println("正在写入 Hive DWD层 ...")
log_product_browse.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.log_product_browse") // 保存到Hive表
println("已完成写入 Hive DWD层")
}
/* 创建scan过滤, 过滤出rowkey包含'20221001'内容的行
* 假设rowkey格式为:创建日期_发布日期_ID_TITLE
* 目标:查找 rowkey中包含 20221001 的数据
* 使用行过滤器:new RowFilter(CompareOp.EQUAL , new SubstringComparator("20221001"))
* 返回 org.apache.hadoop.hbase.client.Scan
*/
def getScan: Scan = {
// 创建Scan
val scan = new Scan()
// 指定行过滤器(行键必须包含子字符串"20221001")
val rowFilter = new RowFilter(CompareOperator.EQUAL, new SubstringComparator("20221001"))
// scan 设置过滤器
scan.setFilter(rowFilter)
scan.withStartRow(Bytes.toBytes("0+20221001000000000")) // 起始行键
scan.withStopRow(Bytes.toBytes("9+20221001235959999")) // 结束行键
scan
}
// 自定义方法:使用 newAPIHadoopRDD 读取数据
def readHBase(spark:SparkSession):DataFrame = {
// 1) 创建HbaseConfiguration配置信息
val hbaseConf = HBaseConfiguration.create()
hbaseConf.set("hbase.zookeeper.quorum", "192.168.190.139") //设置zooKeeper集群地址,也可以通过将hbase-site.xml拷贝到resources目录下
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181") //设置zookeeper连接端口,默认2181
hbaseConf.set("hbase.master", "192.168.190.139:16000") // 设置HBase HMaster
// 设置从HBase哪张表读取数据
val tablename = "ods:product_browse_offline" // 要读取的hbase表名
hbaseConf.set(TableInputFormat.INPUT_TABLE, tablename) // 注意:读取时使用TableInputFormat
// 2)添加filter => TableMapReduceUtil.convertScanToString(getScan)
hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(getScan))
// 3)调用SparkContext中newAPIHadoopRDD读取表中的数据,构建RDD
val resultRDD: RDD[(ImmutableBytesWritable, Result)] = spark.sparkContext.newAPIHadoopRDD(
hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result]
)
// 4)对获取的值进行过滤,并转换为DataFrame返回
import spark.implicits._
resultRDD
.map { t =>
val result = t._2 // 获得Result
val map: collection.mutable.Map[String, String] = collection.mutable.Map() // 存储列限定符和列值
for (cell <- result.rawCells()) {
val colum = Bytes.toString(CellUtil.cloneQualifier(cell)) // 列限定符
val value = Bytes.toString(CellUtil.cloneValue(cell)) // 列值
map.put(colum, value)
}
// 构造为ProductBrowse对象实例
ProductBrowse(log_id=map.get("log_id").get,
product_id=map.get("product_id").get,
customer_id=map.get("customer_id").get,
gen_order=map.get("gen_order").get,
order_sn=map.get("order_sn").get,
modified_time=map.get("modified_time").get
)
}
// 转换为DataFrame
.toDF()
}
}
子任务10
子任务10描述
10、抽取ods 库中表customer_level_inf 最新分区的数据到dwd 库中dim_customer_level_inf 的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等, 并添加dwd_insert_user 、dwd_insert_time 、dwd_modify_user 、dwd_modify_time 四列, 其中dwd_insert_user 、dwd_modify_user 均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),并进行数据类型转换。使用hive cli 执行show partitions dwd.dim_customer_level_inf 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
这个任务需求中没有明确说是增量抽取还是全量抽取,大家在比赛时需要去探索了解。这里我们假设它是全量抽取。
子任务10实现
编写Spark代码,实现数据的转换,并写入到Hive的DWD层。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob10{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 从Hive ODS读取离线订单数据,转换,写入到Hive DWD层
spark.sql("select * from ss2024_ds_ods.customer_level_inf where etl_date='20231225'")
//.show
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// .show
.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.dim_customer_level_inf") // 保存到Hive表
}
}
子任务11
子任务11描述
11、抽取ods 库中表customer_addr 最新分区的数据到dwd 库中dim_customer_addr 的分区表,分区字段为etl_date 且值与ods 库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time 四列,其中dwd_insert_user、dwd_modify_user 均填写“user1”,dwd_insert_time、dwd_modify_time 均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),并进行数据类型转换。使用hive cli 执行show partitions dwd.dim_customer_addr 命令,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下;
子任务11分析
这个任务需求中没有明确说是增量抽取还是全量抽取,大家在比赛时需要去探索了解。这里我们假设它是全量抽取。
子任务11实现
编写Spark代码,实现数据的转换,并写入到Hive的DWD层。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob11{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 从Hive ODS读取离线订单数据,转换,写入到Hive DWD层
spark.sql("select * from ss2024_ds_ods.customer_addr where etl_date='20231225'")
//.show
// 增加新的列
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
// .show
.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dwd.dim_customer_addr") // 保存到Hive表
}
}
子任务12
子任务12描述
12、将dwd 库中dim_customer_inf 、dim_customer_addr 、dim_customer_level_inf 表的数据关联到dws 库中customer_addr_level_aggr 的分区表,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd),并添加dws_insert_user、dws_insert_time、dws_modify_user、dws_modify_time四列, 其中dws_insert_user 、dws_modify_user 均填写“ user1 ” ,dws_insert_time、dws_modify_time 均填写当前操作时间(年月日必须是今天,时分秒只需在比赛时间范围内即可),并进行数据类型转换。使用hive cli 统计最新分区中的数据总量,将结果截图粘贴至客户端桌面【Release\模块D 提交结果.docx】中对应的任务序号下。
子任务12分析
这个子任务要求构建宽表,并存入数据仓库的dws层。
但是,似乎少给了customer_addr_level_aggr表的表结构???
子任务12实现
首先,在Hive CLI命令行,执行如下命令,创建Hive数据仓库DWS:
hive> create database ss2024_ds_dws;
然后,编写Spark代码,实现数据的关联操作,并写入到Hive的DWS层。
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.expressions.Window
object CleaningJob12{
def main(args: Array[String]): Unit = {
// 创建SparkSession实例
val spark = SparkSession.builder()
.master("local[*]")
.appName("Data Clean")
.// 兼容Hive Parquet存储格式
.config("spark.sql.parquet.writeLegacyFormat", true)
// 打开Hive动态分区的标志
.config("hive.exec.dynamic.partition", "true")
.config("hive.exec.dynamic.partition.mode", "nonstrict")
// 启用动态分区覆盖模式(根据分区值,覆盖原来的分区)
.config("spark.sql.sources.partitionOverwriteMode","dynamic")
.config("spark.serializer","org.apache.spark.serializer.KryoSerializer")
.enableHiveSupport()
.getOrCreate()
// 加载数据集,注意对多个数据集中重复的列名进行重命名
val dim_customer_inf_df = spark.table("ss2024_ds_dwd.dim_customer_inf").drop("etl_date")
.withColumnRenamed("dwd_insert_user","inf_dwd_insert_user")
.withColumnRenamed("dwd_insert_time","inf_dwd_insert_time")
.withColumnRenamed("dwd_modify_user","inf_dwd_modify_user")
.withColumnRenamed("dwd_modify_time","inf_dwd_modify_time")
.withColumnRenamed("modified_time","inf_modified_time")
val dim_customer_addr_df = spark.table("ss2024_ds_dwd.dim_customer_addr").drop("etl_date")
.withColumnRenamed("dwd_insert_user","addr_dwd_insert_user")
.withColumnRenamed("dwd_insert_time","addr_dwd_insert_time")
.withColumnRenamed("dwd_modify_user","addr_dwd_modify_user")
.withColumnRenamed("dwd_modify_time","addr_dwd_modify_time")
.withColumnRenamed("modified_time","addr_modified_time")
val dim_customer_level_inf_df = spark.table("ss2024_ds_dwd.dim_customer_level_inf").drop("etl_date")
.withColumnRenamed("dwd_insert_user","level_dwd_insert_user")
.withColumnRenamed("dwd_insert_time","level_dwd_insert_time")
.withColumnRenamed("dwd_modify_user","level_dwd_modify_user")
.withColumnRenamed("dwd_modify_time","level_dwd_modify_time")
.withColumnRenamed("modified_time","level_modified_time")
}
// 执行join连接
val customer_addr_level_aggr_df = dim_customer_inf_df
.join(dim_customer_addr_df, "customer_id")
.join(dim_customer_level_inf_df, "customer_level")
// 将连接的宽表,按要求增加新的列,然后写入到Hive的DWS层
customer_addr_level_aggr_df
// 增加新的列
.withColumn("dws_insert_user",lit("user1"))
.withColumn("dws_insert_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("dws_modify_user",lit("user1"))
.withColumn("dws_modify_time",date_trunc("second",current_timestamp())) // spark 2.3.0
.withColumn("etl_date", lit("20231225"))
// .show
.write
.format("hive")
.mode("overwrite") // 覆盖
.partitionBy("etl_date") // 指定分区
.saveAsTable("ss2024_ds_dws.customer_addr_level_aggr") // 保存到Hive表
}
1 本站一切资源不代表本站立场,并不代表本站赞同其观点和对其真实性负责。
2 本站一律禁止以任何方式发布或转载任何违法的相关信息,访客发现请向站长举报
3 本站资源大多存储在云盘,如发现链接失效,请联系我们我们会第一时间更新。









暂无评论内容